

GPT-5.4正式发布,标志着AI模型向“能力大一统”迈出了关键一步。OpenAI首次将推理、编程、计算机原生交互、深度网页搜索以及百万级上下文窗口等核心能力,深度融合于单一模型之中。
官方特别强调,这种集成并未以牺牲任何单项性能为代价。在多个关键基准测试中,GPT-5.4在相关领域依然保持领先地位。
此次发布最引人注目的,是GPT-5.4成为了首个原生支持“计算机使用”能力的通用模型。这意味着模型能够理解屏幕截图,并通过模拟鼠标点击和键盘输入来操作软件界面。
与此同时,GPT-5.4在效率上实现了显著提升。相比前代模型,其在推理过程中消耗的Token数量显著减少,从而带来了更快的响应速度和更低的整体使用成本。OpenAI反复强调,此次升级是能力提升与效率优化同步进行的结果。
随着GPT-5.4上线,ChatGPT的模型体系也随之更新。新模型已同步在ChatGPT、API及Codex平台推出。在API定价上,虽然GPT-5.4的单Token价格略高于GPT-5.2,但由于完成任务所需的Token更少,总体成本可能不会大幅上升。
面向复杂任务的GPT-5.4 Pro版本也已推出,在ChatGPT中体现为“GPT-5.4 Thinking”。该版本将取代此前的GPT-5.2 Thinking,而GPT-5.2系列将在三个月后正式退役。更早的GPT-5.1系列则将于3月11日从ChatGPT中移除。
GPT-5.4的发布迅速引发了广泛讨论。其集百万级上下文与原生电脑操作能力于一身的特性,被许多评论者视为AI向通用数字助手演进的重要里程碑。


核心能力跃升:三大方向全面进化
GPT-5.4的能力升级主要围绕三个核心方向展开:
* 深度知识工作
* 原生计算机使用
* 高阶编程与调试
这三种能力基本覆盖了当前数字工作的核心流程。
深度知识工作
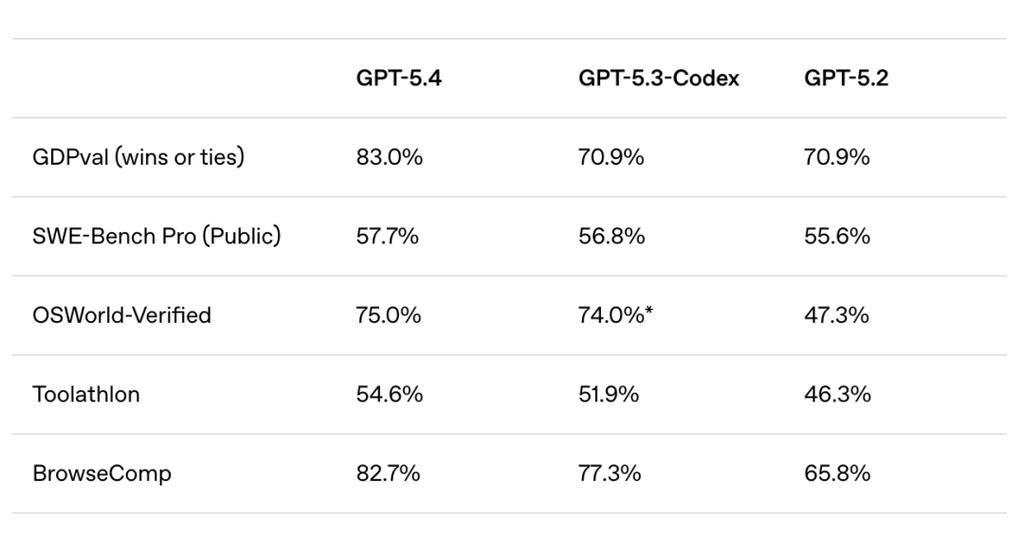
在衡量AI处理44种职业知识工作能力的GDPval基准测试中,GPT-5.4的综合得分达到83.0%。该测试要求模型产出真实的工作成果,如销售演示文稿、会计表格、排班表等。

OpenAI特别强化了模型在办公文档领域的能力。例如,在内部投资银行建模测试中,GPT-5.4的平均得分达到87.3%,显著高于GPT-5.2的68.4%。在人类评审的PPT生成测试中,评委有68%的时间更偏好GPT-5.4生成的结果,认为其在视觉效果、版式丰富度和图片使用上更优。
这些能力直接对应着撰写报告、制作财务模型、分析商业数据等典型的知识型任务场景。

原生计算机使用
这是GPT-5.4区别于以往模型的核心标志。模型能够通过截图理解软件界面,并执行点击、输入等操作,从而完成发送邮件、创建日历、填写表单、操作网页等任务。

在相关基准测试中,GPT-5.4表现突出:在WebArena浏览器任务测试中成功率为67.3%;在仅通过截图完成网页操作的Online-Mind2Web测试中,成功率高达92.8%;在OSWorld-Verified桌面操作测试中,其75.0%的成功率甚至超过了人类平均水平(72.4%)。

高阶编程与调试
GPT-5.4整合了此前最强编程模型的能力,并引入了新的实验性功能。例如,“Playwright (Interactive)”模式允许AI在编写网页或应用时,开启一个可视化窗口进行实时调试。
在SWE-Bench Pro测试中,GPT-5.4取得了57.7%的成绩,略高于前代编程模型,且延迟更低。内部测试显示,其在复杂前端任务中生成的界面设计更美观,功能结构也更完整。
OpenAI通过一个由GPT-5.4生成的浏览器主题公园模拟游戏来演示此能力:模型从简单提示词出发,自主生成资源、构建场景、编写逻辑,并通过自动化测试不断迭代,其工作流已接近高级全栈工程师。


整体定位:迈向“AI数字员工”
综合以上能力可以看出,GPT-5.4的目标是成为一个能够完成真实工作的智能体系统。它正从需要人类密切监督的辅助工具,向能独立负责整块业务的“数字员工”演进。
这种演进主要体现在三个维度的飞跃:
1. 电脑操作能力:通过视觉理解直接操控软件。
2. 浏览器任务能力:在BrowseComp测试中,GPT-5.4达到82.7%的成绩,其Pro版本更是达到89.3%,意味着它能持续搜索、筛选并整合网络信息。
3. 多工具调用能力:在Toolathlon基准测试(任务涉及多步骤操作,如读取邮件附件、上传文件、评分并记录)中,GPT-5.4以54.6%的准确率高于前代的45.7%。这种按需调用工具的能力,是降低智能体运行成本、避免其在复杂任务中“迷路”的关键。


此外,GPT-5.4在对延迟要求较高的场景中也进行了针对性优化。

细节之处的全面进化
除了核心能力,GPT-5.4在办公场景的细节处理上也进行了显著优化。
在电子表格与演示文稿的创建与编辑方面,其表格建模准确率从68.4%提升至87.3%。在演示文稿生成的人类评审中,GPT-5.4的结果在视觉多样性和审美上也更受青睐。
视觉能力的增强进一步提升了文档解析水平。在MMMU-Pro视觉推理基准测试中,GPT-5.4取得了81.2%的准确率,优于GPT-5.2的79.5%。

此外,模型现支持高达1024万像素的原图输入,对高分辨率、高密度图像的理解更为精准。在OmniDocBench文档解析测试中,GPT-5.4的平均错误率从0.140降至0.109。

准确性的提升同样显著。根据官方介绍,GPT-5.4的事实错误概率较前代模型降低了33%,这有助于减轻用户对模型产生“幻觉”的担忧。

在效率优化方面,GPT-5.4引入了工具搜索机制。传统方式需要将所有工具定义置入提示词中,导致提示词冗长。新机制允许模型先获取工具列表,再按需查询具体定义。在MCP Atlas基准测试中,该机制在保持相同准确率的前提下,将总Token使用量降低了47%。这表明OpenAI正致力于通过成本控制推动大模型的规模化商业应用。
性能提升与成本考量
根据OpenAI公布的API定价,GPT-5.4的每百万Token输入/输出费用分别为2.5美元和15美元,高于GPT-5.2的1.75美元和14美元。面向高性能需求的GPT-5.4 Pro版本定价则更高。该版本主要定位专业机构与高端生产力场景。
尽管单价上涨,但GPT-5.4通过技术机制实现了潜在的成本节约。其核心在于前述的工具搜索功能,避免了为未使用的工具定义支付Token费用。在测试中,该技术将总Token使用量降低了47%。

技术前沿的代价
技术的飞速发展也伴随着使用成本的现实考量。有用户分享了使用GPT-5.4 Pro进行简单交互即产生高昂费用的经历,这引发了社区对于“杀鸡焉用牛刀”的讨论——如何根据实际需求合理选择模型版本,成为一个值得思考的问题。


关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/archives/24457
