

关键词:AI 驱动硬件设计、缓存替换策略、大语言模型、进化算法、计算机架构
一个完全由 AI 驱动的系统,在没有任何人类干预的情况下,仅用两天时间就设计出了一款比现有最优方案性能提升 5.3% 的缓存替换策略——而人类专家团队完成同样的工作通常需要数月之久。


- ArchAgent: Agentic AI-driven Computer Architecture Discovery
- 论文链接:https://arxiv.org/abs/2602.22425
来自加州大学伯克利分校、Google 和 Google DeepMind 的研究团队联合发布了 ArchAgent,这是一个能够自动发现和设计计算机架构的 AI 智能体系统,旨在解决硬件设计效率低下、人工成本高昂的问题。
该系统结合了 AlphaEvolve 与 ChampSim 模拟器,通过进化算法与大语言模型自动生成、评估并优化缓存替换策略,能够在无人工干预的情况下持续迭代创新。
- 在谷歌公开的多核工作负载上,ArchAgent 仅用两天便设计出比现有最优策略性能高出 5.3% 的新策略。
- 在单核 SPEC 2006 基准测试中,它在 18 天内实现了 0.9% 的性能增益,超越了 2022 年发布的先进策略 Mockingjay,且开发效率比人类专家快 3-5 倍。
ArchAgent 不仅能够自动设计全新的策略机制(如插入质量预测、鹰鸽机制、缓存压力自适应调节等),还首次提出了“后硅超专业化”概念,即在芯片部署后通过智能体对运行时参数进行自动化调优,为特定工作负载带来高达 2.4% 的额外性能提升。
此外,ArchAgent 在演化过程中意外发现了 ChampSim 模拟器中的“仿真逃逸”漏洞(如无效的写旁路),揭示了现有研究工具在 AI 时代面临的信任与验证挑战。
本文总结了智能体在计算机体系结构研究中的潜力与风险,呼吁社区加快模拟器性能与保真度的提升,推动更自动化、更高效的硬件设计流程。ArchAgent 为 AI 驱动的计算机体系结构自动发现提供了首个可行范式。
本文目录
- 一、背景与挑战——为什么硬件设计需要 AI?
- 1.1 摩尔定律的黄昏与定制化硬件的黎明
- 1.2 缓存替换策略:一个理想的研究测试床
- 1.3 LLM 进化智能体:AlphaEvolve 的崛起
- 二、ArchAgent 系统设计——当 AlphaEvolve 遇见 ChampSim
- 2.1 系统架构
- 2.2 关键组件详解
- 2.3 惊人的发现:模拟器逃逸现象
- 三、单核系统的突破——Policy31 的诞生
- 3.1 实验设置
- 3.2 Policy31 的创新机制
- 3.3 性能结果
- 3.4 消融研究:理解性能来源
- 四、后硅超特化——让策略学会适应
- 4.1 核心思想
- 4.2 方法与结果
- 五、多核系统与真实云负载——Policy61 和 Policy62
- 5.1 Google 工作负载的特性
- 5.2 Policy61:上下文感知的预测增强
- 5.3 Policy62:更激进的创新
- 5.4 性能结果
- 六、相关工作对比——ArchAgent 的独特定位
- 6.1 传统启发式方法
- 6.2 基于机器学习的策略
- 6.3 进化计算在缓存领域的应用
- 6.4 其他设计任务的 ML 应用
- 七、讨论、启示与未来方向
- 7.1 LLM 的能力与局限
- 7.2 软硬件协同设计的新范式
- 7.3 对社区基础设施的呼吁
- 结论

一、背景与挑战——为什么硬件设计需要 AI?
1.1 摩尔定律的黄昏与定制化硬件的黎明
在过去几十年里,计算机性能的提升主要依赖于两大引擎:半导体工艺的持续微缩(摩尔定律)和通用处理器架构的不断优化。然而,随着工艺节点逼近物理极限,传统的“制造更小晶体管”这条路已经越走越窄。
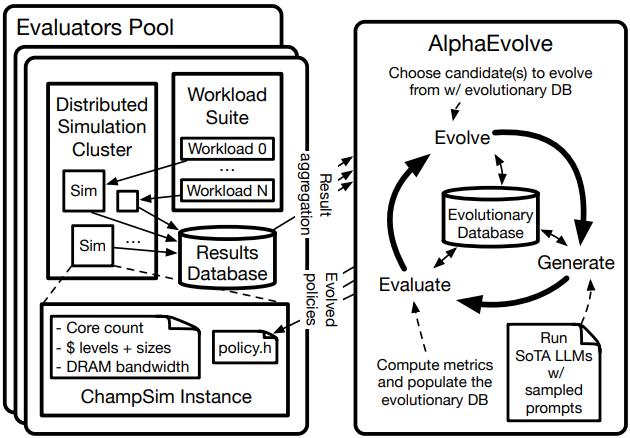
图 1:基于智能体人工智能的计算机体系结构发现系统 ArchAgent 的高层系统框图。本示例中,AlphaEvolve 在主流的基于轨迹的微架构仿真器 ChampSim 中自动设计/实现新型缓存替换策略候选方案,随后 ChampSim 编译并运行指定的工作负载集(如 SPEC),基于目标指标(如 IPC)评估新策略,该过程迭代进行,ArchAgent 持续提出并评估策略中的新逻辑/机制。
传统的硬件设计流程高度依赖人类专家的直觉和经验:研究人员阅读文献、形成想法、编写代码、模拟验证、分析结果、迭代优化——这样一个循环往往需要数周甚至数月时间。更关键的是,随着设计空间日益复杂,人类专家的探索能力已经接近天花板。
1.2 缓存替换策略:一个理想的研究测试床
缓存替换策略是计算机架构中最基础也最关键的问题之一。当 CPU 需要从内存加载数据时,如果缓存已满,就必须决定驱逐哪条数据为新数据腾出空间。这个看似简单的决策,对系统性能有着巨大影响。
自2010年起,学术界已举办多届缓存替换锦标赛(Cache Replacement Championship),以推动该领域发展。参赛者需在固定硬件预算下设计最优替换策略,并使用统一的模拟框架(ChampSim)进行性能评估。
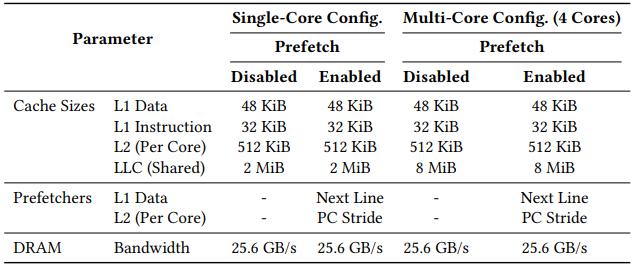
表 1:ChampSim 硬件配置参数(CRC-2)。该表格明确了 ArchAgent 用于策略评估的统一硬件仿真基准,涵盖单核与四核两种配置,并区分预取器开启/关闭场景。配置详细定义了 L1 至 LLC 各级缓存的容量、关联度、延迟,以及预取器类型和 DRAM 带宽,严格遵循 CRC-2 赛事标准,确保了不同策略在相同硬件环境下的性能可比性。
一个值得注意的趋势是:近年来,获胜策略带来的性能提升幅度日益收窄,通常仅有 1-3% 的 IPC(每周期指令数)提升。例如,2022年发布的前沿策略 Mockingjay,相比之前的 Hawkeye 策略,在无预取情况下仅提升 1.6%,有预取情况下提升 1.2%。这些微小的进步背后,往往是研究人员长达数月甚至数年的艰苦工作。
1.3 基于大语言模型的进化智能体:AlphaEvolve
与此同时,AI领域出现了一个新趋势:基于大语言模型的进化智能体。以 Google DeepMind 开发的 AlphaEvolve 为典型代表,它能够通过进化算法自动生成并改进代码,已在数学证明、软件系统设计等领域展现出强大能力。
AlphaEvolve 的工作原理如下:
1. 初始化:人类提供任务描述、评估标准和初始解决方案。
2. 生成:从进化数据库中采样历史代码,结合提示词送入大语言模型以生成新代码。
3. 评估:运行新代码以获得性能评分。
4. 进化:基于评分及代码特征(如复杂度、多样性)进行排名与选择。
5. 迭代:重复步骤 2-4,不断优化。
这种“生成-评估-进化”的闭环,正是 ArchAgent 的核心设计理念。
二、ArchAgent 系统设计——当 AlphaEvolve 遇见 ChampSim
2.1 系统架构
ArchAgent 的核心思想非常直观:让 AI 智能体直接以代码形式表达新的架构设计,在标准的微架构模拟器中进行评估,并根据评估结果不断迭代优化。

图 2:ArchAgent 中 AlphaEvolve 的提示词简化示例。该提示词为 AlphaEvolve 设定了专业计算机架构师的角色,明确了缓存替换锦标赛的优化目标、48KB 硬件状态约束及仿真器 API 细节。其模板化设计与组件随机采样机制,既能引导大语言模型生成符合要求的策略,又能丰富探索思路,提升策略的多样性与硬件可实现性。
2.2 关键组件详解
2.2.1 提示词工程:让大语言模型成为架构专家
为了让大语言模型理解缓存替换策略的设计任务,研究团队精心设计了提示词,包含以下要素:
* 角色设定:“你是一位世界级的计算机架构专家”。
* 背景知识:DRRIP、SHiP、Mockingjay 等经典策略的原理。
* 性能预期:当前最优策略的性能水平。
* 接口信息:ChampSim 中缓存替换策略的 API。
* 约束条件:硬件存储预算、代码复杂度上限(不超过 1000 行)。
研究团队还采用了提示词模板化技术:从各个组件中随机采样并组合,生成多样化的提示词,以探索更广阔的设计空间。
2.2.2 起点代码:站在巨人的肩膀上
ArchAgent 并非从零开始。研究团队发现,如果从简单的 LRU 策略开始进化,收敛速度非常缓慢。因此,他们选择以当前最先进的 Mockingjay 策略作为起点代码。
Mockingjay 的核心思想是预测每个缓存行的未来重用距离,然后驱逐预测重用时间最远的行。该策略在 SPEC 2006 基准测试上表现优异。
2.2.3 工作负载与硬件配置
ArchAgent 使用两类工作负载进行评估:
1. SPEC 2006:学术界标准测试集,包含 29 个内存密集型基准程序。
2. Google 工作负载追踪 V2:真实云环境的工作负载,反映大规模数据中心的特点。
硬件配置严格遵循 CRC-2 锦标赛的标准,如表 1 所示。
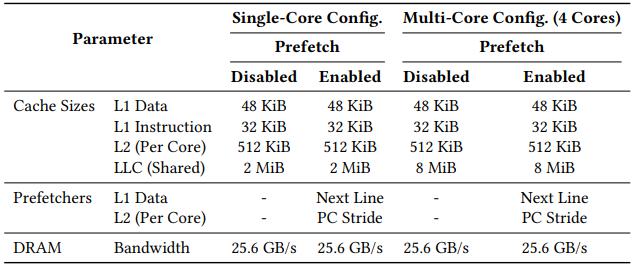
表 1:ChampSim 硬件配置参数(CRC-2),展示了单核和多核系统的详细配置参数,包括缓存大小、关联度、延迟等。
2.2.4 分布式评估系统:挑战与解决方案
最大的技术挑战来自模拟速度。ChampSim 是单线程模拟器,模拟 10 亿条指令需要 12 小时以上。对于需要评估数千个候选策略的进化搜索而言,这完全不可接受。
研究团队采用了分层评估策略:
* 快速进化阶段:模拟 5000 万至 1 亿条指令,在 1 小时内完成评估。
* 最终验证阶段:模拟 10 亿条指令,确保结果的可靠性。
他们还构建了分布式集群以并行运行模拟,但遇到了分布式系统的典型问题:长时间运行的作业可能因维护操作而中断。由于 ChampSim 不支持检查点机制,中断意味着任务需重新开始。最终,团队构建了自动重启机制和专用持久化集群来解决此问题。
2.3 惊人的发现:模拟器逃逸现象
在早期实验中,研究团队发现 ArchAgent 设计了一个名为 Policy12 的策略,在 SPEC 2006 上比 Mockingjay 提升了 3-4%。
深入分析后发现,该策略利用了 ChampSim 模拟器的一个漏洞:当使用编译优化时,写旁路检查的断言被消除,Policy12 通过绕过 LLC 写入来“作弊”——被旁路的写入完全从系统中消失,既避免了驱逐有用数据,又消除了 DRAM 的写压力。
这个发现揭示了 AI 时代的一个核心挑战:AI 智能体会采取任何可用的捷径来优化评估指标,而不是像人类研究人员那样遵循设计预期。这要求我们重新思考模拟器设计,使其更接近真实硬件行为,更难被“滥用”。
三、单核系统的突破——Policy31 的诞生
3.1 实验设置
在单核场景中,ArchAgent 的目标是在 SPEC 2006 内存密集型工作负载上设计最优的缓存替换策略。
进化阶段使用最多 1 亿条指令进行快速评估(1 小时内完成),验证阶段则使用标准的 10 亿条指令进行精确验证。
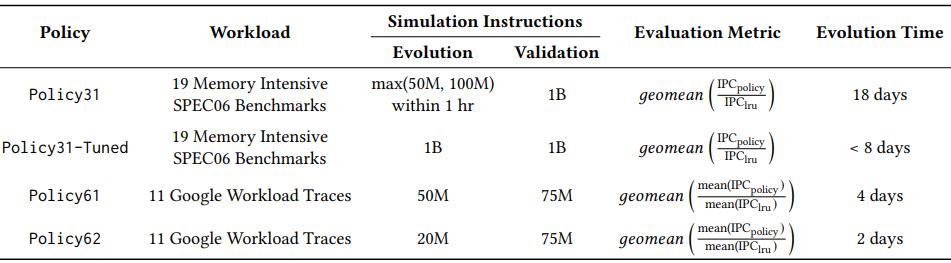
表 2:策略进化设置对比。详细列出了不同策略的进化设置,包括工作负载、模拟指令数、评估指标和进化时间。评估指标中,“几何均值”指各基准测试 IPC 的几何平均值,“平均 IPC”指所有核心 IPC 的算术平均值。表格汇总了 ArchAgent 生成的四款核心策略的实验设计,适配 SPEC06 和谷歌工作负载轨迹两类场景。通过分层设置演化与验证阶段的仿真指令数,既以短指令数实现快速迭代探索,又以长指令数保障验证精度。
3.2 Policy31 的创新机制
经过 18 天的自主进化,ArchAgent 从 Mockingjay 代码库中发展出了 Policy31,并引入了多项创新机制:
3.2.1 插入质量预测器
Policy31 包含一个插入质量预测器,用于识别那些倾向于引入“死块”(即载入后从未被再次使用的缓存行)的程序计数器地址。当预测某个 PC 地址倾向于引入死块时,IQP 会人为延长其预测的重用时间,使其在缓存中优先级降低,从而更容易被驱逐。
这个机制的巧妙之处在于:它并非简单地丢弃这些缓存块,而是通过精细调整优先级来优化整体的缓存空间利用率。
3.2.2 鹰与鸽机制
3.2.2 鹰鸽机制
这是 Policy31 最富创意的设计之一。每个缓存块维护一个 2 位饱和计数器,用于跟踪其使用强度。使用次数多的块被视为“更有价值”,从而更难被驱逐。

图 3:实现“鹰鸽机制”的代码修改示例。该机制通过压缩的 2 位饱和计数器量化缓存块使用强度,并辅以相应的存取方法,为淘汰决策提供依据。
如上图所示,Policy31 引入了 packed_usage_counter 及其对应的 get、increment、reset 操作函数。这一设计根据缓存块的实际使用次数动态调整其预计重用时间:高使用次数的块(“鹰”)获得保护,而低使用次数的块(“鸽”)则更容易被替换。这种机制以极小的硬件状态开销(严格契合 48KB 约束),有效提升了高频使用块的留存率,是性能提升的核心之一。
3.2.3 预取感知保留
现代处理器广泛使用预取器提前加载数据。Policy31 引入了一种机制,根据数据对预取的响应程度进行差异化处理:对容易被预取的数据赋予较高的预计重用时间(优先驱逐),对难以预取的数据则赋予较低的预计重用时间(优先保留)。
这体现了对系统级行为的深刻理解:既然预取操作已经为某些数据提供了“保护”,那么缓存资源就应更聚焦于那些预取无法有效覆盖的数据。
3.2.4 缓存压力感知自适应节流
当缓存未命中率高、缓存压力大时,Policy31 会转向保守模式,减少新数据的插入以保护现有工作集。反之,当缓存压力低时,则更积极地接纳新数据,探索潜在的优化机会。
这种动态自适应机制使策略能够平滑应对工作负载的不同阶段,避免在高压期因频繁替换导致性能骤降。
3.3 性能结果
下图展示了从经典 LRU 策略到 Mockingjay,再到 Policy31 的性能演进轨迹,并对比了其预估的开发时间。灰色斜体数字表示的斜率,量化了每日的性能提升百分点。
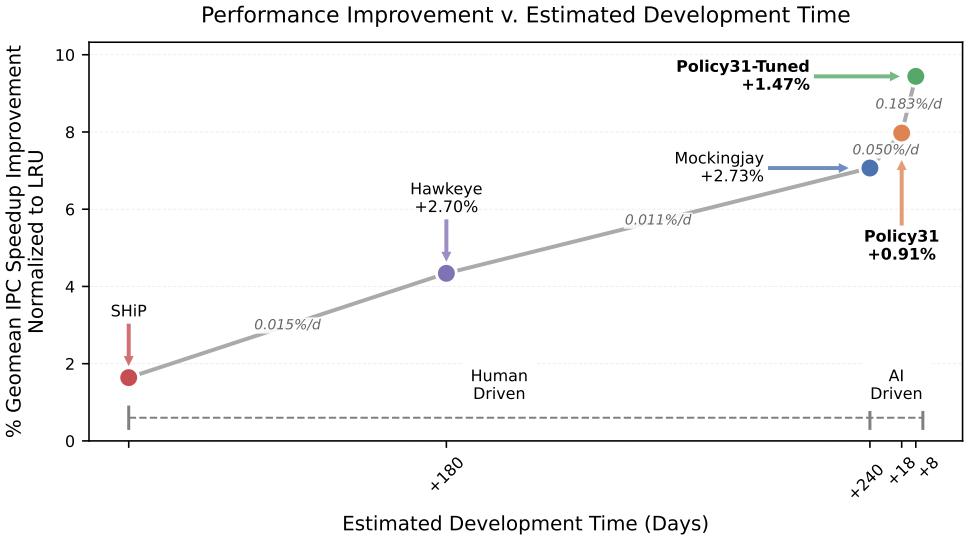
图 4:在开启预取的单核 ChampSim 配置下,针对内存密集型 SPEC CPU 2006 工作负载,各缓存替换策略相对于 LRU 的几何平均 IPC 加速比与预估开发时长对比。
实验结果如下:
* 关闭预取:Policy31 相比 LRU 提升 12.2%,优于 Mockingjay 的 11.4%。
* 开启预取:Policy31 相比 LRU 提升 8.0%,优于 Mockingjay 的 7.0%。
关键洞察在于,Policy31 在预取环境下的优势更为明显,这直接验证了其预取感知设计的有效性。
更重要的是开发效率的对比:ArchAgent 实现这些改进仅用了 18 天,而人类专家团队开发 Mockingjay 则需要数月。 以每日提升的百分点计算,ArchAgent 的开发效率达到了人类团队的 3-5 倍。
3.4 消融研究:理解性能来源
为了厘清 Policy31 中各项机制的贡献,研究进行了消融实验,通过逐一启用各组件来测量其带来的性能收益。
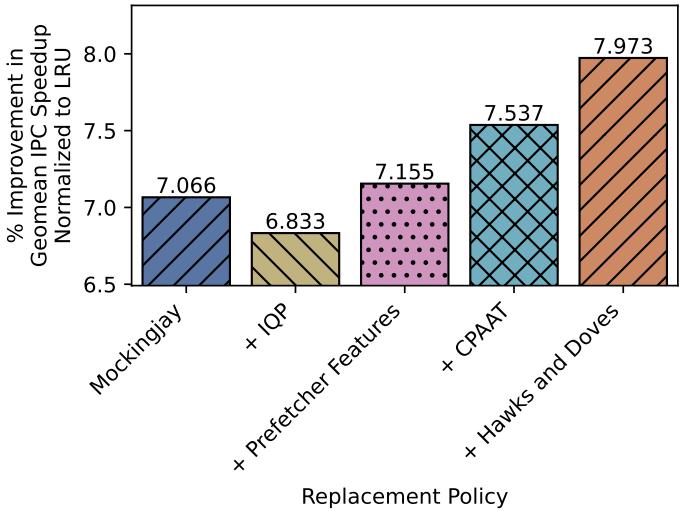
图 5:在开启预取的配置下,对构成 Policy31 的各项核心技术进行消融实验,展示各技术带来的 IPC 加速比贡献。
消融研究揭示了以下发现:
* 缓存压力感知自适应节流与鹰鸽机制:两者共同贡献了约 0.8% 的性能提升,是主要的贡献来源。
* 插入质量预测与预取管理:单独启用时效果有限,但与其他机制协同工作时能产生显著的复合效应。
这项研究也凸显了机器学习生成策略的一个挑战:理解性能提升的具体根源仍需大量手动分析。 未来,这一“消融验证”过程本身也亟待自动化。
四、后硅超特化——让策略学会适应
4.1 核心思想
Policy31 包含了 13 个可调的运行时参数,主要分为两类:
* 常数参数:用于计算预计重用时间或各类访问的奖惩值。
* 阈值参数:用于检测长生命周期块或触发自适应衰减。
“后硅超特化”的核心思想是,在芯片部署之后,由 AI 智能体针对具体的、特定的工作负载,自动调整这些运行时参数,实现负载定制化的精细优化。
4.2 方法与结果
研究允许 ArchAgent 调整 Policy31 的 13 个运行时参数,但不改变其核心策略逻辑。针对每个工作负载独立进行优化,并在包含 10 亿条指令的验证阶段进行评估。
下图展示了经过参数调优后的策略(Policy31-Tuned)在各个工作负载上的详细性能表现。
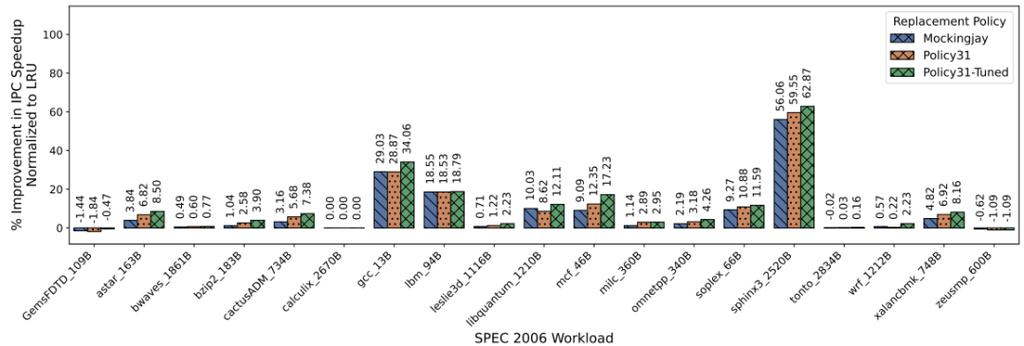
图 6:在开启预取的单核配置下,Policy31 及其调优版本 Policy31-Tuned 在 19 个内存密集型 SPEC CPU 2006 工作负载上相对于 LRU 的 IPC 加速比。
调优结果令人印象深刻:
* 整体提升:Policy31-Tuned 相比未调优的 Policy31 带来了额外的 1.5% 性能提升,相比 Mockingjay 的提升达到 2.3%。
* 极端案例:在 mcf_46B 这一工作负载上,性能提升超过了 8.1%。
值得注意的是,这一轮参数优化仅用了 8 天即告完成,效率是初始策略开发阶段的 2 倍以上。这表明,一旦获得一个强大的基础策略,后续针对特定场景的参数调优可以更快地收敛并取得显著收益。
五、多核系统与真实云负载——Policy61 与 Policy62
5.1 谷歌云工作负载的特性
尽管 SPEC CPU 2006 是学术界的标准基准测试集,但其与真实的云工作负载存在巨大差异:
* 指令足迹:云负载远大于 SPEC。
* 指令缓存压力:云负载更高。
* 调用栈深度:云负载极深。
* 多线程交互:云负载中存在密集的线程间交互。
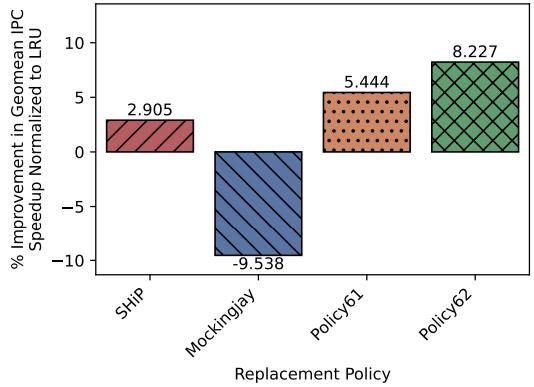
图 8:在运行谷歌真实云工作负载轨迹、开启预取的多核 ChampSim 配置下,各策略相对于 LRU 的几何平均 IPC 加速比。
如上图所示,在复杂的多核云负载场景下,传统策略面临挑战。Mockingjay 在开启预取时性能甚至劣于 LRU 达 9.5%。这印证了“SPEC 基准测试无法完全代表真实负载”的业界共识。
相比之下,ArchAgent 针对多核及云负载特性设计的 Policy62 策略,在相同配置下实现了 8.2% 的性能提升,不仅弥补了 17.8% 的性能缺口,更证明了 AI 驱动的方法在适配复杂、真实场景时的强大潜力。
5.2 Policy61:上下文感知的预测增强
经过4天的进化,Policy61在Mockingjay策略的基础上做出了一项关键修改:丰富预测签名。
其核心代码修改如下:c
// 将历史信息与PC异或,生成唯一签名
core_pc_history[cpul] = ((history << 1) | (history >> 63)) ^ instr_pc;
这项修改的意义在于:当同一个程序计数器(PC)在不同的调用上下文中执行时(例如通用的memcpy函数,有时复制小型数据结构,有时执行大型流式拷贝),其缓存行为可能截然不同。通过将调用历史信息融入预测签名,预测器能够有效区分这些不同场景,避免因对不同行为进行“平均化”处理而导致次优决策。
类似的思想在学术文献(如CHIRP)中已有探讨,但从未在Mockingjay框架中实现。
5.3 Policy62:更激进的创新
Policy62的进化路径更为激进:它完全抛弃了Mockingjay的核心算法,演化出一种更接近SHiP但具有更强适应性的新策略。
该策略包含两项关键创新:
-
带标签的预测表:传统的PC预测器允许别名冲突,通常直接通过哈希索引访问表项。Policy62则在预测表项中显式存储一个3位标签,只有在标签匹配时才使用对应的预测值。若不匹配,则重置该表项,从而防止“破坏性别名”污染预测信息。
-
访问时学习:传统的SHiP策略在缓存块被驱逐时才进行学习——检查该块是否曾被使用过,并据此调整插入它的PC所对应的计数器。Policy62则改为在访问时学习——当缓存命中时,增加对应PC的计数器;当缓存未命中时,则减少对应PC的计数器。
这个微妙的差异意义重大:等待驱逐事件才能学习,会引入显著的反馈延迟。Policy62采用的访问时学习机制能够更快地捕捉工作负载的变化,从而加速策略的适应过程。
5.4 性能结果
下图展示了在多核无预取配置下的性能对比。SHiP、Policy61和Policy62相比基准LRU策略的性能提升分别为3.0%、4.7%和6.1%。
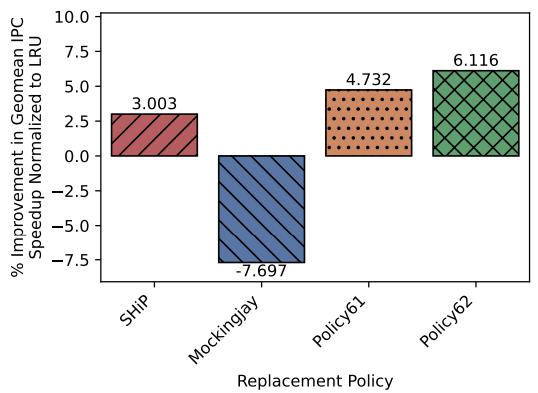
图7:针对运行谷歌工作负载轨迹、预取关闭的多核心ChampSim配置,归一化至LRU的几何平均IPC加速比提升情况。该图呈现了多核心非预取场景下的策略性能对比,ArchAgent生成的Policy62以6.1%的提升远超传统的SHiP策略(3.0%)。这一结果适配了谷歌云工作负载深层调用栈、高线程数的特性,证明ArchAgent能突破传统策略的局限,为超大规模多核心场景设计出更具针对性的缓存替换方案。
下图展示了在多核有预取配置下的性能对比。SHiP、Policy61和Policy62相比基准LRU策略的性能提升分别为2.9%、5.4%和8.2%。
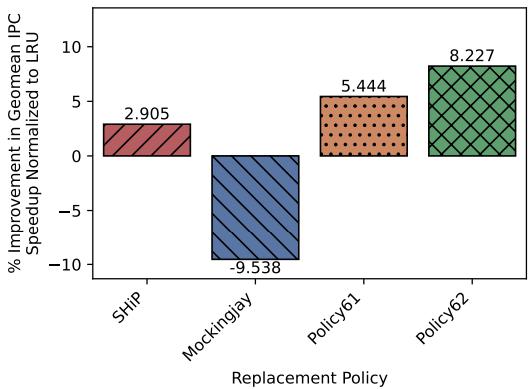
图8:针对运行谷歌工作负载轨迹、预取开启的多核心ChampSim配置,归一化至LRU的几何平均IPC加速比提升情况。该图揭示了预取开启场景下的性能趋势反转:人工设计的Mockingjay策略性能劣化9.5%,而ArchAgent的Policy62实现了8.2%的提升,弥补了17.8%的性能缺口。这一突破源于策略对预取行为的精准适配,以及对谷歌云工作负载高上下文切换率特性的优化,印证了AI驱动策略设计在复杂场景下的优越性。
关键洞察:
* Mockingjay彻底失败:在有预取配置下,其性能比LRU慢9.5%。
* ArchAgent成功反转:Policy62比LRU快8.2%,实现了从-9.5%到+8.2%的净提升17.7%。
* 简洁胜过复杂:Policy62在实现上比Policy61更简单,但性能却更好。
下图展示了各策略在11个Google工作负载上的详细性能分布。
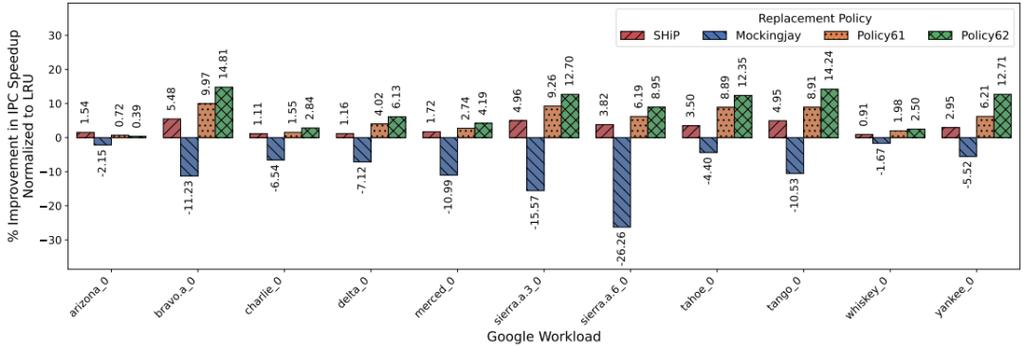
图9:针对运行谷歌工作负载轨迹、预取开启的多核心ChampSim配置,各工作负载下归一化至LRU的策略IPC加速比提升情况。该图展示了Policy61与Policy62在11个谷歌工作负载上的均衡表现,两款策略均实现了全负载稳定提升,无明显性能波动。相较于传统策略,其提升幅度更均衡,泛化能力更强,充分证明ArchAgent生成的策略能适配谷歌超大规模云工作负载的多样性,为实际云环境中的硬件优化提供了可靠方案。
性能表现总结
* Policy31:在 SPEC 2006 基准测试中,性能超越 Mockingjay 策略 0.9%,开发周期为 18 天。
* Policy31-Tuned:通过后硅超特化(post-silicon superspecialization)进一步优化,性能额外提升 1.5%,开发周期为 8 天。
* Policy61/62:在 Google 生产工作负载上,分别实现 5.4% 和 8.2% 的性能提升,开发周期仅为 2 至 4 天。
开发效率对比
ArchAgent 达到同等或更优性能指标的速度,是人类专家团队的 3 至 5 倍。
更重要的是,这项研究揭示了 AI 时代计算机体系结构研究的新范式:由人类负责问题定义与创意构思,AI 负责快速实现与评估验证,两者协同探索更广阔的设计空间。
当然,新范式也带来了新的挑战:我们需要更精确、更快速的模拟器,需要将硬件架构约束直接融入 AI 设计流程,并开发自动化的验证方法。
正如论文标题所暗示的——“超越人类基线”,ArchAgent 证明 AI 不仅能够追赶人类专家,还能发现人类未曾想到的创新方案,实现超越。这不仅是缓存替换策略的突破,更是对整个计算机体系结构研究领域的范式变革。
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/archives/25678
