

驱动具身智能迈向通用领域的核心挑战是什么?
我们认为,关键在于实现“跨具身迁移”。
一个完善的世界模型是具身智能执行通用复杂任务的基础。然而,许多现有的世界模型并不具备我们所期望的强大泛化与迁移能力。
具体而言,当前应用于机器人或智能汽车的世界模型,大多针对特定硬件平台进行设计和训练,其泛化能力有限,跨平台迁移往往依赖运气。
本质上,许多机器人学习到的并非“世界如何运作”,而是“这台特定机器如何运动”。我们需要一个能够真正理解物理规律与因果关系的世界模型——它需要知晓世界状态如何变化、动作会引发何种后果——才能在不同“身体”和不同环境中实现有效的迁移与泛化。
针对这一难题,深耕于各类世界模型的英伟达再次取得突破,构建了一个全新的、完全基于零样本范式的世界模型。
近期,英伟达GEAR实验室提出了DreamZero,这是一种基于预训练视频扩散骨干网络构建的世界动作模型。
这是一个拥有140亿参数的模型,能够让机器人仅通过简单的文本提示,就完成此前从未接触过的任务。
实验室负责人Jim Fan将其称为机器人领域的“GPT-2时刻”:研究团队只需输入想法,机器人就能执行相应动作。目前,该模型的代码已在GitHub上开源。



- 论文标题:World Action Models are Zero-shot Policies
- 论文链接:https://dreamzero0.github.io/DreamZero.pdf
- Github 链接:https://github.com/dreamzero0/dreamzero
与传统视觉-语言-动作模型不同,WAM通过联合预测未来世界状态与动作来学习物理动力学,并以视频作为世界演化的稠密表示。通过对视频与动作的联合建模,DreamZero能够从异构机器人数据中高效学习多样化技能,而不依赖重复示范。在真实机器人实验中,相比最先进的VLA模型,DreamZero在新任务与新环境的泛化上实现了超过2倍的性能提升。
至关重要的是,通过模型与系统层面的优化,研究团队让一个140亿参数的自回归视频扩散模型实现了7Hz的实时闭环控制。此外,研究团队展示了两种跨具身迁移能力:仅使用10–20分钟的人类或其他机器人纯视频示范,即可在未见任务上带来超过42%的性能提升。更令人惊讶的是,DreamZero只需30分钟的“玩耍数据”,就能适配到全新的机器人平台,同时仍保持零样本泛化能力。

DreamZero 整体概览。
图中展示了DreamZero通过联合预测视频与动作,世界动作模型继承了关于世界物理规律的先验,从而实现了:
1. 从多样、非重复的数据中高效学习;
2. 在开放世界场景中的强泛化能力;
3. 仅依赖纯视频数据即可完成跨具身学习;
4. 对新机器人的少样本快速适配。

DreamZero 的模型架构。
大多数预训练的视频扩散模型凭借来自网页规模数据的丰富时空先验,成为构建机器人策略的理想骨干网络。然而,将这类模型转化为高效的世界动作模型仍面临关键挑战:
1. 视频–动作对齐:联合预测视频与动作要求对视觉未来与电机指令进行紧密耦合,但如果只是简单地将独立的视频头与动作拼接,往往会导致二者对齐失效;
2. 架构设计:尚不清楚双向架构还是自回归架构更适合WAM,这关系到多模态对齐、误差累积以及推理效率等关键问题;
3. 实时推理:视频扩散模型需要在高维潜空间中进行多步迭代去噪,使其在闭环控制场景下速度过慢、难以实用。
为此,DreamZero通过模型设计选择有效应对了上述挑战。
模型接收三类输入:视觉上下文(通过VAE编码)、语言指令(通过文本编码器)、以及本体感知状态(通过状态编码器)。这些输入随后被送入一个基于Flow Matching的自回归DiT主干网络,由其联合预测未来的视频帧与动作,并通过各自独立的解码器输出结果。
在训练阶段,模型以分块的方式工作:在给定干净视频上下文作为条件的情况下,对加噪的视频与动作潜变量进行去噪。在推理阶段,模型的预测会以异步方式在真实世界中执行,同时将真实观测结果回灌到KV缓存中,以防止误差随时间累积。
实验结果
研究团队在六种设置下展示了DreamZero的能力——其中五种用于测试泛化,一种用于实时部署。
相关的训练数据以及实验结果的演示可以参考以下链接:
https://dreamzero0.github.io/evals_gallery/
AgiBot预训练:已见 & 未见任务
研究团队对预训练模型进行开箱即用评测:任务来自预训练分布,但在未见对象的新环境中进行零样本测试。DreamZero(也包含从零训练版本)取得62.2%的平均任务进度,相比最佳预训练VLA基线(27.4%)提升超过2倍。从零训练的VLA几乎为零;预训练VLA有一定进展,但幅度有限。

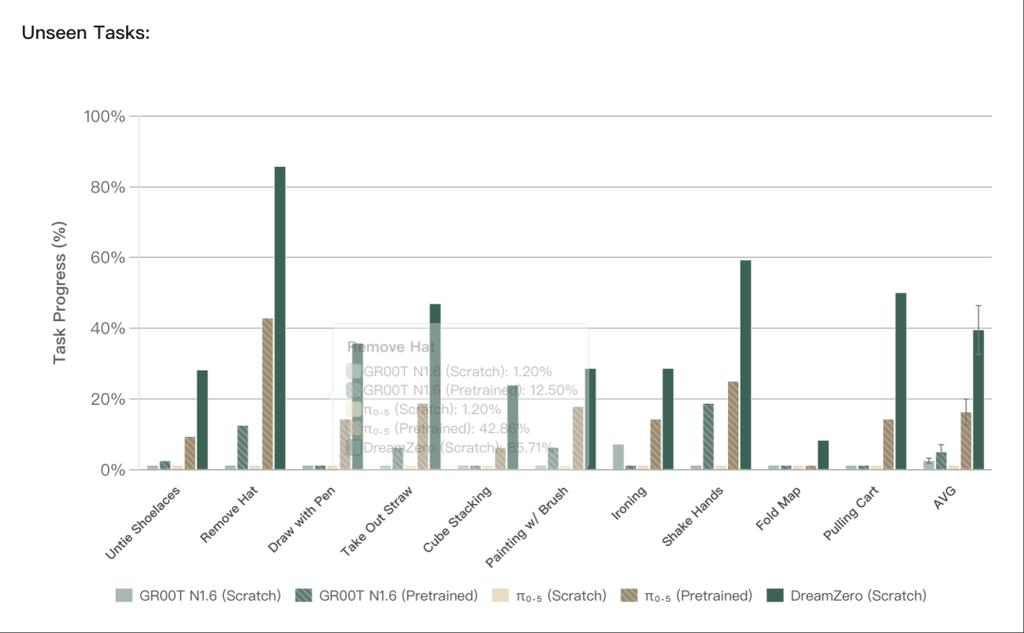
对于训练中完全未出现的任务(如解鞋带、握手),DreamZero仍达到39.5%的任务进度,而VLA再次表现吃力。值得注意的是,预训练VLA在未见任务上的有限进展,主要源于其无论指令如何都倾向于执行“抓取-放置”的默认动作,显示其过拟合于主导训练行为,而非真正理解新任务语义。研究团队在4台机器人、不同环境与物体上,对每个检查点进行了80次rollouts。
DROID:已见任务 & 未见动作
为验证在公开数据上的效果,研究团队在DROID(最异构的开源机器人数据集之一)上训练DreamZero,并评测20个已见任务与20个未见动词任务(DROID中未出现的动作)。DreamZero显著优于预训练基线,在未见动词上取得49%的任务进度,而最先进的VLA仅为25–32%。

后训练:分布外泛化
本部分研究WAM在任务特定微调后是否仍保留泛化能力。研究团队在三项下游任务上进行后训练:叠衬衫、装水果、清理餐桌。DreamZero在三项任务上均表现更强,表明后训练后仍保持环境泛化能力。
跨具身迁移
仅用30分钟的玩耍数据(55条轨迹),DreamZero即可适配YAM机器人,并对南瓜、泰迪熊、纸袋等新物体实现零样本泛化,同时展现出强大的语言指令遵循能力。来自AgiBot预训练的知识可直接迁移,无需大规模重训。这是目前效率最高的具身迁移:以往需要数百小时示范的工作,能够在30分钟内完成(未使用任何其他YAM数据)。
交互式提示
机器人基础模型的“提示时代”已经到来。研究团队展示了交互式提示的实战:带着机器人走到不同地方,让人们直接用语言提出新任务。机器人能够完成多种令人惊喜的操作。
实时推理
通过模型、系统与实现层面的优化,DreamZero实现了每个动作块150ms的实时推理,支持7Hz闭环控制。结合异步推理与动作块平滑,执行过程更加流畅、响应迅速。研究团队对比了16/4/1个扩散步数的效果:步数越少延迟越低,而DreamZero-Flash即便在单步推理下也能保持性能。研究团队还展示了动作块平滑与异步推理对执行质量的影响。
DreamZero (16 diffusion step) + async & action chunk smoothing
零样本泛化能走多远?研究团队持续对 DreamZero 进行压力测试,在从未训练过的任务、从未见过的环境中探索其能力边界。从翻转汉堡、按下电梯按钮,到敲击木琴、摇动铃鼓,模型不断涌现出令人惊讶的新技能。
DreamZero 只是一个开始——它代表了基于视频世界模型的新一代机器人基础模型浪潮。
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/archives/20883
