

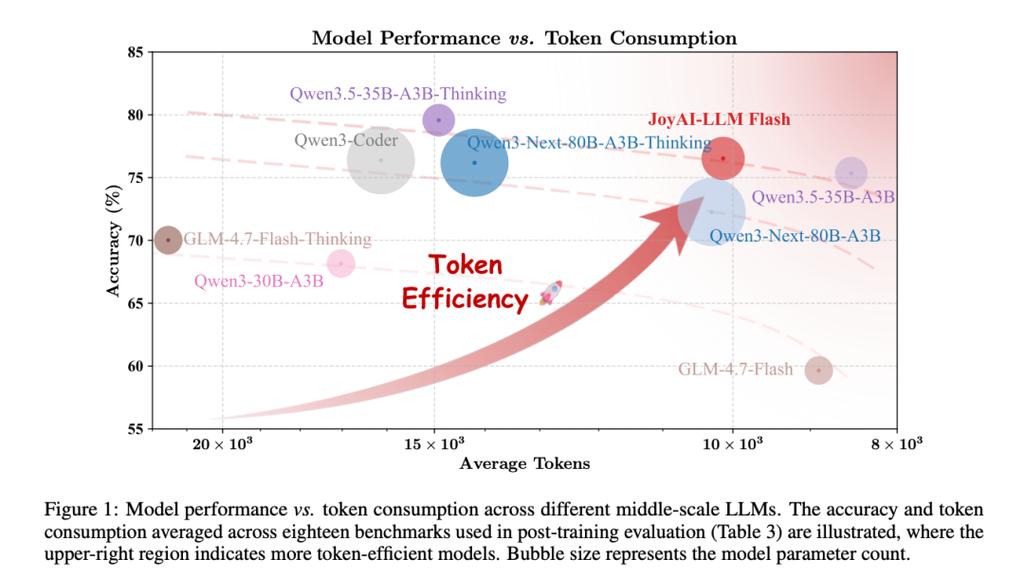
一个拥有480亿参数的大模型,每次推理仅激活其中2.7B参数——稀疏率超过94%。在18个基准测试的平均表现中,它以更低的token消耗达到了与同级甚至更大模型相当或更优的准确率。这就是京东发布的JoyAI-LLM Flash。
论文指出,当前大语言模型面临两大交织挑战:token效率低下与计算成本高昂。JoyAI-LLM Flash正是为此而生——一个在50B参数以下区间重新定义性能与token效率平衡的MoE(混合专家)语言模型。

极致稀疏的架构设计
论文详细阐述了JoyAI-LLM Flash的架构配置:模型共40层Transformer,第一层为标准密集前馈网络,其余39层为稀疏MoE层。MoE模块采用细粒度设计,包含256个专家。每个token通过Top-8门控机制动态选择8个路由专家,并加上1个共享专家,总计激活9个专家。模型隐藏维度为2048,词表大小129K,最大上下文长度128K。

论文指出,模型采用Muon优化器替代传统Adam,该优化器通过矩阵正交化进行参数优化,在实验中不仅加速了收敛,且训练全程未出现明显的损失尖峰。此外,模型附加了单层密集MTP(多token预测)头,训练时丰富学习信号,推理时原生支持投机解码。
20万亿token的四阶段预训练
JoyAI-LLM Flash Base在超过20万亿token的纯文本语料上完成预训练,学习率调度采用Warmup-Constant-Cosine-Decay,分为四个阶段:
1. 基础阶段:建立通用语言能力。
2. 代码-数学增强阶段:大幅提升代码与数学数据比例。
3. 中期训练阶段:聚焦超高质量token以精炼推理能力,合成数据占比提升至60%以上。
4. 长上下文阶段:将上下文窗口扩展至128K。
数据来源涵盖网络爬取、代码仓库、PDF文档和大规模合成数据。论文在网络数据处理上采用MinHashLSH去重(Jaccard相似度阈值0.9),并训练专用BERT分类器进行语义安全过滤。

后训练:从SFT到FiberPO
论文将大量计算预算分配给后训练阶段,依次经过SFT(监督微调)、DPO(直接偏好优化)和RL(强化学习)三个阶段。
SFT阶段刻意交错“思考”与“非思考”认知模式的数据,这种混合训练显著提升了指令模型的非思考能力。训练数据涵盖数学、编码、工具使用、安全、创意写作等领域,其中编码和智能体数据占比约30%。

FiberPO是论文提出的核心RL算法创新,灵感来自纤维丛理论。它将信任域维护分解为全局(轨迹级)和局部(token级)两个组件,提供多尺度稳定性控制。这种分解带来三个关键性质:轨迹独立性、一阶一致性、尺度分离。


推理加速与量化
在MTP效率上,JoyAI-LLM Flash实现了1.87倍加速。在8K输入/16K输出设置下,相比GLM-4.7-Flash和Qwen3-30B-A3B分别获得1.45倍和1.07倍的速度提升。

论文同时采用QAT(量化感知训练)和PTQ(训练后量化)。PTQ实验显示,FP8量化带来17%吞吐提升且几乎无精度损失,W4AFP8量化实现近28%吞吐提升,精度仅下降1.2%。

最终效果

在LiveCodeBench上,JoyAI-LLM Flash以65.6%准确率超越GLM-4.7-Flash-Thinking的64.0%,同时token消耗仅为后者的约14%(7300 vs 53600)。在SWE-bench Verified上达到62.6%,在MATH-500达到98.2%。
当94%的参数在每次推理中保持静默,剩下6%却能交出超越同级别模型的答卷——这或许就是稀疏架构真正的力量。论文指出,未来将通过整合持续学习与持久记忆来扩展模型范式。

原文标题:JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
原文链接:https://arxiv.org/abs/2604.03044huggingface地址:https://huggingface.co/collections/jdopensource/joyai-llm-flash
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/archives/28952
