

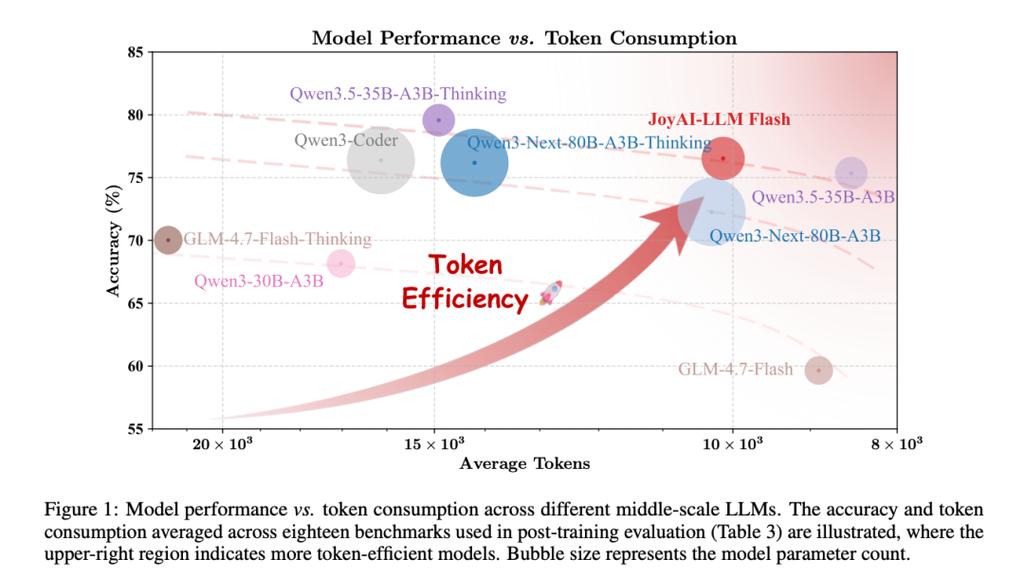
โมเดลขนาดใหญ่ที่มีพารามิเตอร์ 48 พันล้านตัว แต่ในแต่ละการอนุมานจะเปิดใช้งานพารามิเตอร์เพียง 2.7 พันล้านตัวเท่านั้น ซึ่งมีความเบาบางมากกว่า 94% จากผลการทดสอบมาตรฐาน 18 รายการโดยเฉลี่ย โมเดลนี้ใช้โทเค็นน้อยกว่า แต่ได้ความแม่นยำเทียบเท่าหรือดีกว่าโมเดลในระดับเดียวกันหรือแม้แต่โมเดลที่ใหญ่กว่า นี่คือ JoyAI-LLM Flash ที่ JD.com เปิดตัว
เอกสารวิจัยชี้ให้เห็นว่าโมเดลภาษาขนาดใหญ่ในปัจจุบันเผชิญกับความท้าทายหลักสองประการที่เกี่ยวพันกัน: ประสิทธิภาพการใช้โทเค็นต่ำและต้นทุนการคำนวณสูง JoyAI-LLM Flash ถูกสร้างขึ้นเพื่อแก้ไขปัญหานี้โดยเฉพาะ—มันคือโมเดลภาษาแบบ MoE (Mixture of Experts) ที่กำหนดนิยามใหม่ของสมดุลระหว่างประสิทธิภาพและประสิทธิภาพการใช้โทเค็นในกลุ่มโมเดลที่มีพารามิเตอร์ต่ำกว่า 50B

การออกแบบสถาปัตยกรรมแบบเบาบางขั้นสูง
เอกสารวิจัยอธิบายรายละเอียดการกำหนดค่าสถาปัตยกรรมของ JoyAI-LLM Flash: โมเดลมี Transformer ทั้งหมด 40 ชั้น ชั้นแรกเป็น Feedforward Network แบบหนาแน่นมาตรฐาน ส่วนอีก 39 ชั้นที่เหลือเป็นชั้น MoE แบบเบาบาง โมดูล MoE ใช้การออกแบบแบบละเอียด (fine-grained) ประกอบด้วยผู้เชี่ยวชาญ 256 คน สำหรับแต่ละโทเค็น จะเลือกผู้เชี่ยวชาญ 8 คนผ่านกลไกเกต Top-8 แบบไดนามิก และเพิ่มผู้เชี่ยวชาญร่วม (shared expert) อีก 1 คน รวมเป็นผู้เชี่ยวชาญที่ถูกเปิดใช้งาน 9 คน โมเดลมีมิติซ่อน (hidden dimension) 2048 ขนาดคำศัพท์ 129K และความยาวบริบทสูงสุด 128K

เอกสารวิจัยชี้ให้เห็นว่าโมเดลใช้ตัวเพิ่มประสิทธิภาพ Muon แทน Adam แบบดั้งเดิม ตัวเพิ่มประสิทธิภาพนี้ทำการเพิ่มประสิทธิภาพพารามิเตอร์ผ่านการทำให้เมทริกซ์ตั้งฉาก (matrix orthogonalization) ในการทดลองไม่เพียงแต่เร่งการลู่เข้าเท่านั้น แต่ยังไม่พบการพุ่งสูงขึ้นของค่าความสูญเสีย (loss spike) ที่ชัดเจนตลอดกระบวนการฝึก นอกจากนี้ โมเดลยังเพิ่มหัวทำนายหลายโทเค็น (Multi-token Prediction – MTP) แบบหนาแน่นชั้นเดียวเข้าไป ซึ่งช่วยเพิ่มสัญญาณการเรียนรู้ระหว่างการฝึก และรองรับการถอดรหัสแบบคาดการณ์ (speculative decoding) โดยธรรมชาติระหว่างการอนุมาน
การฝึกล่วงหน้าสี่ขั้นตอนด้วยโทเค็นกว่า 20 ล้านล้านตัว
JoyAI-LLM Flash Base ผ่านการฝึกล่วงหน้าบนคลังข้อความล้วนที่มีโทเค็นมากกว่า 20 ล้านล้านตัว โดยใช้การกำหนดอัตราการเรียนรู้แบบ Warmup-Constant-Cosine-Decay แบ่งออกเป็นสี่ขั้นตอน:
1. ขั้นพื้นฐาน: สร้างความสามารถทางภาษาทั่วไป
2. ขั้นเสริมรหัสและคณิตศาสตร์: เพิ่มสัดส่วนข้อมูลรหัสและคณิตศาสตร์อย่างมาก
3. ขั้นฝึกกลาง: มุ่งเน้นโทเค็นคุณภาพสูงพิเศษเพื่อขัดเกลาความสามารถในการให้เหตุผล สัดส่วนข้อมูลสังเคราะห์เพิ่มขึ้นเป็นมากกว่า 60%
4. ขั้นบริบทยาว: ขยายหน้าต่างบริบทเป็น 128K
แหล่งข้อมูลครอบคลุมการรวบรวมจากเว็บ, คลังรหัส, เอกสาร PDF และข้อมูลสังเคราะห์ขนาดใหญ่ เอกสารวิจัยใช้ MinHashLSH สำหรับการกำจัดข้อมูลซ้ำซ้อนในการประมวลผลข้อมูลเว็บ (เกณฑ์ความคล้าย Jaccard 0.9) และฝึกตัวแยกประเภท BERT เฉพาะทางสำหรับการกรองความปลอดภัยเชิงความหมาย

การฝึกหลัง: ตั้งแต่ SFT ถึง FiberPO
เอกสารวิจัยจัดสรรงบประมาณการคำนวณจำนวนมากให้กับขั้นตอนการฝึกหลัง ผ่านสามขั้นตอนตามลำดับ: SFT (Supervised Fine-Tuning), DPO (Direct Preference Optimization) และ RL (Reinforcement Learning)
ในขั้น SFT จงใจสลับข้อมูลระหว่างโหมดการรับรู้แบบ “คิด” และ “ไม่คิด” การฝึกแบบผสมนี้ช่วยเพิ่มความสามารถแบบไม่คิดของโมเดลตามคำสั่งอย่างมีนัยสำคัญ ข้อมูลการฝึกครอบคลุมด้านคณิตศาสตร์, การเขียนโค้ด, การใช้เครื่องมือ, ความปลอดภัย, การเขียนเชิงสร้างสรรค์ เป็นต้น โดยข้อมูลการเขียนโค้ดและเอเจนต์คิดเป็นประมาณ 30%

FiberPO เป็นนวัตกรรมอัลกอริทึม RL หลักที่เสนอในเอกสารวิจัย ได้รับแรงบันดาลใจจากทฤษฎีมัดไฟเบอร์ (fiber bundle theory) มันแยกการบำรุงรักษาโดเมนความเชื่อมั่น (trust region) ออกเป็นสององค์ประกอบ: ระดับโลก (ระดับ trajectory) และระดับท้องถิ่น (ระดับโทเค็น) เพื่อให้การควบคุมความเสถียรหลายสเกล การแยกย่อยนี้นำมาซึ่งคุณสมบัติสำคัญสามประการ: ความเป็นอิสระของ trajectory, ความสอดคล้องอันดับหนึ่ง, และการแยกสเกล


การเร่งการอนุมานและการควอนไทซ์
ในด้านประสิทธิภาพ MTP, JoyAI-LLM Flash บรรลุการเร่งความเร็ว 1.87 เท่า ภายใต้การตั้งค่าอินพุต 8K/เอาต์พุต 16K เมื่อเทียบกับ GLM-4.7-Flash และ Qwen3-30B-A3B ได้รับการเร่งความเร็ว 1.45 เท่า และ 1.07 เท่า ตามลำดับ

เอกสารวิจัยใช้ทั้ง QAT (Quantization-Aware Training) และ PTQ (Post-Training Quantization) การทดลอง PTQ แสดงให้เห็นว่าการควอนไทซ์ FP8 ให้การเพิ่มปริมาณงาน (throughput) 17% โดยแทบไม่สูญเสียความแม่นยำ ส่วนการควอนไทซ์ W4AFP8 บรรลุการเพิ่มปริมาณงานเกือบ 28% โดยความแม่นยำลดลงเพียง 1.2%

ผลลัพธ์สุดท้าย

บน LiveCodeBench, JoyAI-LLM Flash ได้ความแม่นยำ 65.6% แซงหน้า GLM-4.7-Flash-Thinking ที่ 64.0% ในขณะที่การใช้โทเค็นมีเพียงประมาณ 14% ของ GLM (7300 vs 53600) บน SWE-bench Verified บรรลุ 62.6% และบน MATH-500 บรรลุ 98.2%
เมื่อพารามิเตอร์ 94% ยังคงเงียบในแต่ละการอนุมาน แต่ 6% ที่เหลือสามารถส่งมอบคำตอบที่เหนือกว่าโมเดลในระดับเดียวกันได้—นี่อาจเป็นพลังที่แท้จริงของสถาปัตยกรรมแบบเบาบาง เอกสารวิจัยชี้ให้เห็นว่าในอนาคตจะขยายขอบเขตโมเดลผ่านการผสานการเรียนรู้อย่างต่อเนื่องและความทรงจำถาวร

ชื่อบทความต้นฉบับ: JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
ลิงก์ต้นฉบับ: https://arxiv.org/abs/2604.03044
⚠️ หมายเหตุ: เนื้อหาได้รับการแปลโดย AI และตรวจสอบโดยมนุษย์ หากมีข้อผิดพลาดโปรดแจ้ง
☕ สนับสนุนค่ากาแฟทีมงาน
หากคุณชอบบทความนี้ สามารถสนับสนุนเราได้ผ่าน PromptPay

本文来自网络搜集,不代表คลื่นสร้างอนาคต立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/th/archives/28953