

用Claude Code写论文?这个开源项目把整套流水线打包了,学生党狂喜
用Claude Code撰写论文的完整工作流,已经有人开源打包了。
这完全戳中了学生群体的核心痛点,GitHub星标数已飙升至6.4k。
项目名为academic-research-skills(以下简称ARS),是一套专门为Claude Code设计的技能包。
它内置了4个核心技能模块,分别对应论文的研究、写作、审稿、定稿四个关键环节。
只需两行命令即可完成安装,一键串联起整个学术研究流水线。
说实话,我读研那会儿怎么就没遇上这种神器呢…
4个技能模块,打通科研全流程
ARS的核心架构由4个技能模块构成,它们各司其职,组合在一起就是一条从选题到交稿的完整链路。
我特意做了张图,方便大家直观理解:
**


△**AI生成
Deep Research 是一支由13个Agent组成的研究团队。
它负责文献调研、研究问题构建、方法论设计,还能撰写系统性的PRISMA综述。
团队中设有专门的文献溯源Agent,会调用Semantic Scholar API来验证每一篇引用的真实性。
还有苏格拉底导师Agent,通过对话引导研究者理清思路。
此外,魔鬼代言人Agent专门负责挑刺,防止研究者在早期阶段陷入思维定式。
**

△**AI生成
Academic Paper 是一支由12个Agent组成的写作团队。
从大纲设计、论证构建、草稿撰写,到双语摘要生成、图表可视化、引用格式转换,全流程覆盖。
特别值得一提的是风格校准功能:AI会学习你过往作品的写作风格,让输出更贴近你的个人特色,而不是千篇一律的AI味道。
输出格式支持Markdown、DOCX、LaTeX,最终可以编译成APA 7.0或IEEE格式的PDF。
**

△**AI生成
Academic Paper Reviewer 是一支由7个Agent组成的审稿团队。
它模拟真实学术期刊的评审流程,由主编EIC带领三位领域审稿人,再加上一个魔鬼代言人,从方法论、学科视角、跨学科价值等多个维度进行打分。
评分采用0到100的量化标准:80分以上接受,65到79分小修,50到64分大修,50分以下拒稿。
审稿团队还会输出详细的修改路线图,告诉作者下一步该做什么。
**

△**AI生成
Academic Pipeline 是流程编排器,将前面三个团队串联成一条10阶段的流水线。
从研究、写作、完整性检查、同行评审、修订、最终检查,到发表准备和流程总结,每个阶段都有明确的产物和检查点。
你可以在任意阶段插入:比如已经有了初稿,就从Stage 2.5的完整性检查开始;收到了审稿意见,直接从Stage 4的修订切入。
费用参考也很透明:一篇1.5万字的论文,全程跑下来大约只需4到6美元。
**

△**AI生成
比较有意思的设计
用Claude Code做学术研究的开源项目已经不少了,但深入挖掘后,我发现ARS在底层设计上确实有些过人之处。
可以简单总结为一句话:系统性防止AI搞砸学术研究。
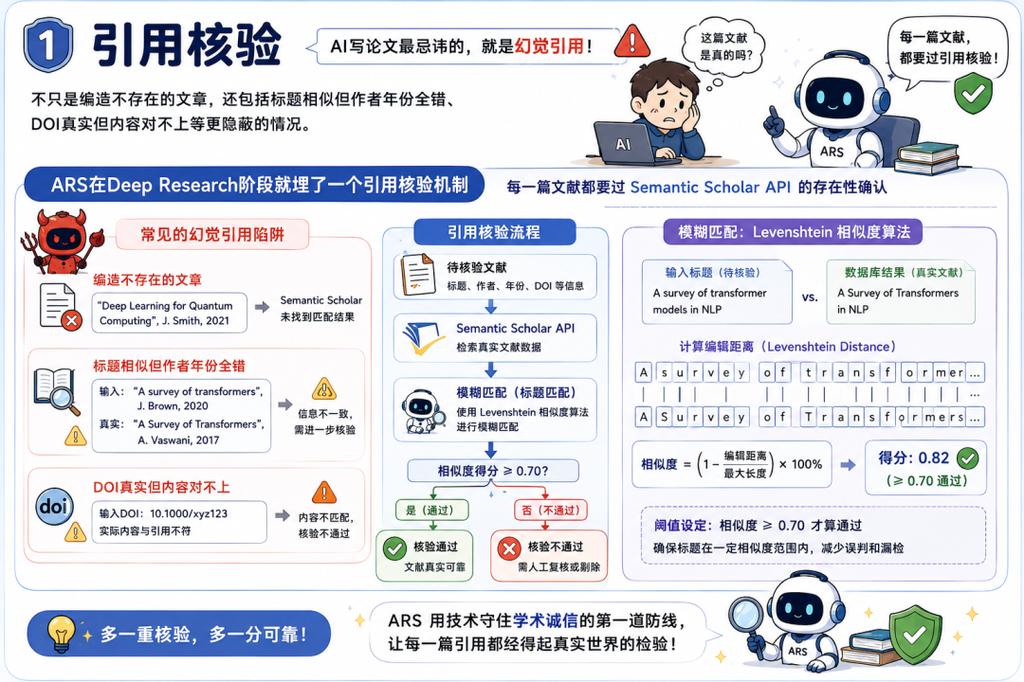
第一,引用核验。
AI写论文最忌讳的就是幻觉引用。
这不仅仅是编造不存在的文章,还包括标题相似但作者年份全错、DOI真实但内容对不上等更隐蔽的情况。
ARS在Deep Research阶段就内置了一个引用核验机制:每一篇文献都必须通过Semantic Scholar API的存在性确认。
不是简单查一下标题对不对,而是用Levenshtein相似度算法做模糊匹配,阈值设在0.70以上才算通过。
**
△**AI生成
第二,完整性闸门。
在流水线的Stage 2.5和Stage 4.5,有两道不可跳过的完整性闸门,会运行一份7项AI失败模式检查清单。
这份清单直接来自2026年Nature上发表的一项全自主AI科研研究,其中总结了7种翻车模式,覆盖引用幻觉、数据捏造、方法论造假等情形。
任何在2.5阶段被标记为SUSPECTED的问题,必须在4.5阶段变成CLEAR,或者由人工手动覆盖并留下记录。
设计逻辑是:把「我相信AI不会出错」变成「我要求AI证明它没出错」。
实测中,这套机制在一篇真实论文里抓到了15个伪造引用和3个统计错误。
第三,反谄媚协议,让AI敢于说不。
大多数AI工具都有一个隐形毛病:讨好用户。你让它改,它就改,哪怕改得更差。
所以ARS在审稿环节专门设计了反谄媚机制。
审稿团队里有一个Devil’s Advocate,也就是魔鬼代言人,职责是挑刺。
但挑完刺之后,还有一个让步阈值协议。
DA的反驳会被评分1到5分,如果低于4分,写作团队不允许承认。
**

△**AI生成
换句话说,AI不能为了显得好合作就轻易让步。
同时,攻击强度在修订过程中必须保持。如果第一轮审稿把方法论批得体无完肤,作者修订后不能让审稿人突然变得温柔。
评分轨迹也会被追踪,任何维度的分数下降都会被标记为回归。
这和软件工程里的不引入新Bug原则一样:改一个地方不能搞砸另一个地方。
第四,三层数据隔离,不让AI偷看答案。
ARS把数据流严格分成三层:
Layer 1是原始输入,默认不可信,可能幻觉、过时、带偏见。
Layer 2是通过完整性验证后的产物。
Layer 3是评分标准、参考答案和金标数据,这层材料永远不能出现在写作AI的上下文中。
具体实现上,写作团队和审稿团队分两次独立调用,中间有阶段边界隔离。
写作AI只能收到审稿AI的自然语言反馈,比如「第二章论证跳跃,建议补充对比实验」。
但它看不到原始的评分标准,也不知道每个维度占多少分。
这个设计的灵感来自于Anthropic今年的w2s-researcher研究,其中也用了同样的三层隔离模型。
结论是:当AI能读取标签数据时,结果可能不是真的泛化,而是在优化表面特征。
解决方案不是更好的提示词,而是结构上的隔离。
**

△**AI生成
最后一点,诚实文档化,「我不保证能复现」。
学术界经常遇到「这个结果我复现不了」的问题。ARS给每个产物生成一个repro_lock文件,记录运行时的完整配置。
但文件里有一段强制声明:LLM输出不是字节级可复现的,模型提供商会更新权重而不改模型ID,外部API每天返回不同的数据。
这个文件只是配置文档,不是重放保证。
**

△**AI生成
在更新日志上,可以看到ARS已经经历了很多轮迭代。从2月上线到现在,提交的commit数达到了三百多次。
从每次版本更迭中,也能看出作者对AI学术研究系统风险有着深刻理解。
这也是我觉得目前学术研究AI工具的关键所在——
让AI帮你写论文并不难,重点是如何防止它出错、讨好,让整个流程变得更系统更可靠。
ARS的设计哲学,可以总结为README里那句话:
「AI是你的副驾驶,不是飞行员。」
如何安装
安装方式很简单,如果你已经在用Claude Code,只需要两行命令:
/plugin marketplace add Imbad0202/academic-research-skills
/plugin install academic-research-skills
验证安装是否成功,运行:
/ars-plan
然后描述你正在写的论文主题,ARS就会启动苏格拉底对话,帮你梳理论文结构。
如果你偏好单条命令测试,也可以用:
/ars-lit-review “你的研究主题”
不过最简单的安装办法,其实是直接把SKILL.md上传到claude.ai项目知识库。
不需要安装Claude Code,打开浏览器就能用。
但需注意,该方案并不支持多Agent并行运行,本质上是单Agent版本,适合轻度体验;若要运行完整的流水线,仍须借助Claude Code。
此外,该项目也支持繁体中文和英文。
接下来,就到了大家最关心的环节——费用问题。
作者推荐搭配 Claude Opus 4.7 与 Max订阅计划 使用。
完整运行10个阶段,单次可消耗超过20万输入token与10万输出token;若单独使用某个子模块,消耗则大幅减少。
Max订阅计划分为两档:每月100美元或200美元,价格并不便宜。
但如果你的科研经费可以报销,那另当别论。
最后,聊聊项目作者。
他是 Edward Cheng-I Wu(吴政宜),头像是一个戴着猫猫图案的可爱男生。
他来自中国台湾。在 GitHub 上,他还开发了台湾正式文件写作 Skill(公文、存证信函、合约)、本地数据匿名化工具等项目。
项目地址:
https://github.com/Imbad0202/academic-research-skills
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/archives/35080
