


经过多日预热,12月22日,智谱AI正式发布新一代旗舰模型GLM-4.7。该模型在编程和复杂推理能力上实现重大突破,旨在对标当前顶尖闭源模型。
基准测试表现亮眼
根据官方信息,GLM-4.7在编程、复杂推理和工具使用方面均有显著提升,同时在聊天、创意写作和角色扮演等场景下的能力也有所增强。
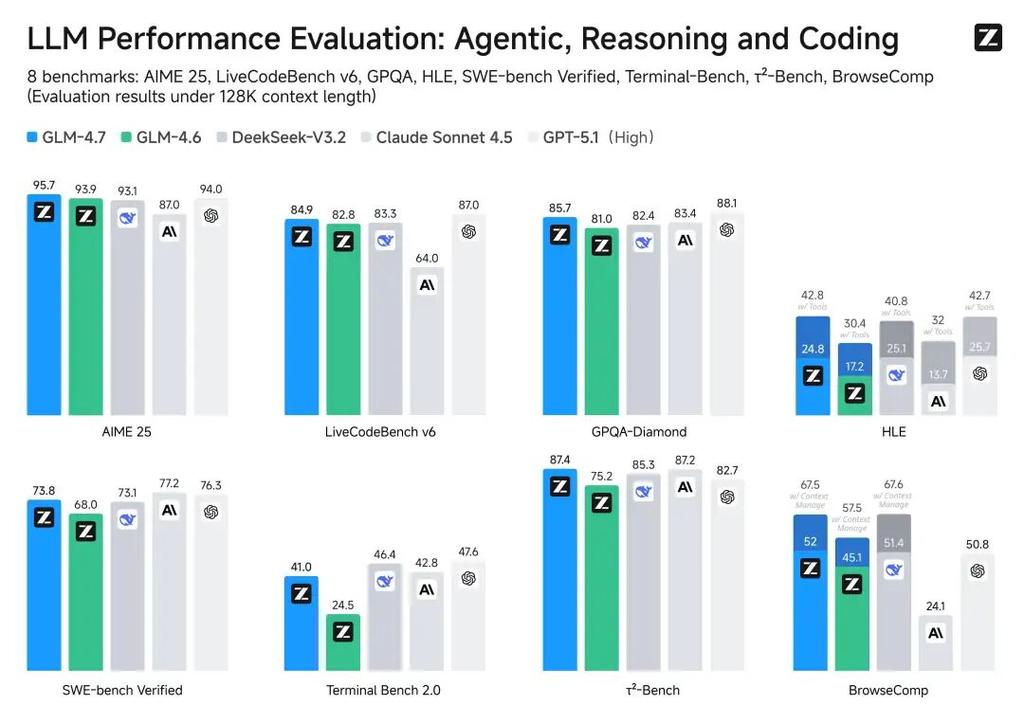
官方公布的测试结果显示,GLM-4.7在多项关键基准测试中表现优异:
- LMArena代码竞技场(盲测):在开源模型中排名第一,超越GPT-5.2。
- LiveCodeBench V6:得分84.8,超过Claude 4.5 Sonnet。
- AIME 2025(数学):表现优于Claude 4.5 Sonnet和GPT-5.1。
- 人类终极考试(HLE):得分42%,比GLM-4.6提升38%,接近GPT-5.1水平。
- τ²-Bench:在真实世界交互任务中与Claude 4.5 Sonnet持平。

在实际开发场景的对比中,GLM-4.7在前端任务上以64.6%的胜率领先GLM-4.6,后端任务胜率为46.7%,指令遵循任务胜率为58.3%。

技术规格与特性
GLM-4.7支持200K上下文长度,最大输出128K tokens,处理速度达到每秒55+ tokens。该模型进一步优化了交织思维模式,并引入了保留思维和回合级思维机制。通过在执行动作之间进行思考并保持跨回合的一致性,使复杂任务的处理更加稳定和可控。

定价策略
GLM-4.7已成为GLM Coding Plan的默认模型。该计划提供多种订阅选项,起价为每月3美元,兼容Claude Code、Cursor等10多种编程工具。
小结
GLM-4.7在基准测试中数据亮眼。据部分内测用户反馈,其真实编程水平确有显著提升,被认为可能迎来又一个“DeepSeek时刻”。然而,也有部分早期用户的测试反馈相对保守,表示在有限测试中,GLM-4.7的表现并未明显优于Claude 4.5 Sonnet或GPT-5.2,甚至可能不及Minimax M2.1。
智谱AI当前密集的模型发布节奏,让部分用户感叹“接受不了,GLM-4.6还没熟悉,GLM-4.7就来了”。这一策略或与智谱AI寻求提升市场竞争力有关。该公司已宣布将于明年1月在香港进行IPO。有市场观点认为,面对同样计划在港股上市、且海外市场影响力更强的竞争对手,智谱AI需要通过快速迭代和性能提升来增强其国际影响力。
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/14761
