

อะไรคือความท้าทายหลักในการขับเคลื่อนปัญญาประดิษฐ์เชิงรูปธรรมไปสู่ขอบเขตสากล?
เราคิดว่าปัจจัยสำคัญอยู่ที่การทำให้เกิด “การถ่ายโอนข้ามรูปธรรม”
โมเดลโลกที่สมบูรณ์เป็นพื้นฐานสำหรับปัญญาประดิษฐ์เชิงรูปธรรมในการปฏิบัติงานที่ซับซ้อนและเป็นสากล อย่างไรก็ตาม โมเดลโลกจำนวนมากในปัจจุบันยังขาดความสามารถในการสรุปและถ่ายโอนที่แข็งแกร่งตามที่เราต้องการ
กล่าวโดยเจาะจง โมเดลโลกที่ใช้กับหุ่นยนต์หรือรถยนต์อัจฉริยะในปัจจุบัน ส่วนใหญ่ได้รับการออกแบบและฝึกฝนสำหรับแพลตฟอร์มฮาร์ดแวร์เฉพาะ ทำให้ความสามารถในการสรุปมีจำกัด และการถ่ายโอนข้ามแพลตฟอร์มมักขึ้นอยู่กับโชค
โดยพื้นฐานแล้ว หุ่นยนต์หลายตัวไม่ได้เรียนรู้ว่า “โลกทำงานอย่างไร” แต่เรียนรู้ว่า “เครื่องจักรเฉพาะนี้เคลื่อนไหวอย่างไร” เราต้องการโมเดลโลกที่เข้าใจกฎฟิสิกส์และความสัมพันธ์เชิงเหตุผลอย่างแท้จริง — มันต้องรู้ว่าสถานะของโลกเปลี่ยนแปลงอย่างไร การกระทำจะนำไปสู่ผลลัพธ์ใด — เพื่อให้สามารถถ่ายโอนและสรุปได้อย่างมีประสิทธิภาพใน “ร่างกาย” และสภาพแวดล้อมที่แตกต่างกัน
เพื่อแก้ไขปัญหาที่ยากลำบากนี้ NVIDIA ซึ่งมีความเชี่ยวชาญในโมเดลโลกประเภทต่างๆ ได้ทำการก้าวข้ามอีกครั้ง โดยสร้างโมเดลโลกใหม่ที่อิงตามกระบวนทัศน์แบบ zero-shot ทั้งหมด
เมื่อเร็วๆ นี้ ห้องปฏิบัติการ GEAR ของ NVIDIA ได้เสนอ DreamZero ซึ่งเป็นโมเดลการกระทำของโลกที่สร้างขึ้นจากเครือข่ายกระดูกสันหลังแบบ diffusion วิดีโอที่ผ่านการฝึกฝนล่วงหน้า
นี่คือโมเดลที่มีพารามิเตอร์ 14 พันล้านตัว ซึ่งทำให้หุ่นยนต์สามารถทำงานที่ไม่มีประสบการณ์มาก่อนได้เพียงผ่านคำสั่งข้อความง่ายๆ
Jim Fan หัวหน้าห้องปฏิบัติการเรียกสิ่งนี้ว่า “ช่วงเวลา GPT-2” ในวงการหุ่นยนต์: ทีมวิจัยเพียงแค่ป้อนความคิด และหุ่นยนต์ก็สามารถดำเนินการตามนั้นได้ ปัจจุบัน โค้ดของโมเดลนี้ได้เปิดตัวบน GitHub แล้ว



- ชื่อบทความวิจัย: World Action Models are Zero-shot Policies
- ลิงก์บทความวิจัย: https://dreamzero0.github.io/DreamZero.pdf
- ลิงก์ Github: https://github.com/dreamzero0/dreamzero
แตกต่างจากโมเดลการมองเห็น-ภาษา-การกระทำแบบดั้งเดิม WAM เรียนรู้พลวัตทางกายภาพโดยการทำนายร่วมกันระหว่างสถานะโลกในอนาคตและการกระทำ และใช้วิดีโอเป็นตัวแทนที่หนาแน่นของวิวัฒนาการของโลก ด้วยการสร้างโมเดลร่วมกันระหว่างวิดีโอและการกระทำ DreamZero สามารถเรียนรู้ทักษะที่หลากหลายจากข้อมูลหุ่นยนต์ที่ต่างกันได้อย่างมีประสิทธิภาพ โดยไม่ต้องพึ่งพาการสาธิตซ้ำๆ ในการทดลองกับหุ่นยนต์จริง เมื่อเทียบกับโมเดล VLA ที่ทันสมัยที่สุด DreamZero บรรลุประสิทธิภาพที่เพิ่มขึ้นมากกว่า 2 เท่าในการสรุปงานใหม่และสภาพแวดล้อมใหม่
ที่สำคัญ ผ่านการปรับปรุงในระดับโมเดลและระบบ ทีมวิจัยทำให้โมเดล diffusion วิดีโอแบบ autoregressive ขนาด 14 พันล้านพารามิเตอร์ บรรลุการควบคุมวงปิดแบบเรียลไทม์ที่ 7Hz นอกจากนี้ ทีมวิจัยยังแสดงความสามารถในการถ่ายโอนข้ามรูปธรรมสองรูปแบบ: การใช้เพียงการสาธิตวิดีโอบริสุทธิ์จากมนุษย์หรือหุ่นยนต์อื่นเป็นเวลา 10–20 นาที สามารถเพิ่มประสิทธิภาพได้มากกว่า 42% ในงานที่ไม่เคยเห็นมาก่อน และที่น่าประหลาดใจยิ่งกว่านั้น DreamZero ต้องการเพียง “ข้อมูลการเล่น” 30 นาที เพื่อปรับให้เข้ากับแพลตฟอร์มหุ่นยนต์ใหม่ ในขณะที่ยังคงความสามารถในการสรุปแบบ zero-shot

ภาพรวมของ DreamZero
ภาพแสดงให้เห็นว่า DreamZero ผ่านการทำนายร่วมกันระหว่างวิดีโอและการกระทำ โมเดลการกระทำของโลกได้สืบทอดความรู้เบื้องต้นเกี่ยวกับกฎฟิสิกส์ของโลก ซึ่งทำให้สามารถ:
1. เรียนรู้ได้อย่างมีประสิทธิภาพจากข้อมูลที่หลากหลายและไม่ซ้ำซาก
2. ความสามารถในการสรุปที่แข็งแกร่งในสถานการณ์โลกเปิด
3. สามารถเรียนรู้ข้ามรูปธรรมได้โดยอาศัยข้อมูลวิดีโอบริสุทธิ์เท่านั้น
4. การปรับตัวอย่างรวดเร็วด้วยตัวอย่างเพียงเล็กน้อยสำหรับหุ่นยนต์ใหม่

โครงสร้างโมเดลของ DreamZero
โมเดล diffusion วิดีโอที่ผ่านการฝึกฝนล่วงหน้าส่วนใหญ่ ด้วยความรู้เบื้องต้นด้านกาลอวกาศที่อุดมสมบูรณ์จากข้อมูลขนาดเว็บไซต์ ได้กลายเป็นเครือข่ายกระดูกสันหลังในอุดมคติสำหรับการสร้างกลยุทธ์หุ่นยนต์ อย่างไรก็ตาม การเปลี่ยนโมเดลดังกล่าวให้เป็นโมเดลการกระทำของโลกที่มีประสิทธิภาพยังคงเผชิญกับความท้าทายสำคัญ:
1. การจัดแนววิดีโอ–การกระทำ: การทำนายร่วมกันระหว่างวิดีโอและการกระทำต้องการการเชื่อมโยงอย่างใกล้ชิดระหว่างอนาคตทางภาพและคำสั่งมอเตอร์ แต่หากเพียงแค่เชื่อมต่อส่วนหัววิดีโอและการกระทำที่เป็นอิสระเข้าด้วยกัน มักจะนำไปสู่ความล้มเหลวในการจัดแนวทั้งสอง
2. การออกแบบโครงสร้าง: ยังไม่ชัดเจนว่าโครงสร้างแบบสองทิศทางหรือแบบ autoregressive เหมาะสมกว่าสำหรับ WAM ซึ่งเกี่ยวข้องกับปัญหาสำคัญ เช่น การจัดแนวหลายรูปแบบ การสะสมข้อผิดพลาด และประสิทธิภาพการอนุมาน
3. การอนุมานแบบเรียลไทม์: โมเดล diffusion วิดีโอต้องการการกำจัดสัญญาณรบกวนแบบหลายขั้นตอนในพื้นที่แฝงมิติสูง ทำให้ช้าเกินไปและใช้งานได้ยากในสถานการณ์ควบคุมวงปิด
เพื่อแก้ไขปัญหาดังกล่าว DreamZero ได้รับมือกับความท้าทายเหล่านี้อย่างมีประสิทธิภาพผ่านทางเลือกในการออกแบบโมเดล
โมเดลรับข้อมูลสามประเภท: บริบทภาพ (ผ่านการเข้ารหัส VAE) คำสั่งภาษา (ผ่านตัวเข้ารหัสข้อความ) และสถานะการรับรู้ภายใน (ผ่านตัวเข้ารหัสสถานะ) ข้อมูลเหล่านี้จะถูกป้อนเข้าสู่เครือข่ายหลัก DiT แบบ autoregressive ที่อิงตาม Flow Matching ซึ่งทำนายร่วมกันระหว่างเฟรมวิดีโอในอนาคตและการกระทำ และส่งออกผลลัพธ์ผ่านตัวถอดรหัสที่เป็นอิสระของแต่ละส่วน
ในขั้นตอนการฝึก โมเดลทำงานแบบแบ่งส่วน: เมื่อกำหนดบริบทวิดีโอที่ชัดเจนเป็นเงื่อนไข จะทำการกำจัดสัญญาณรบกวนของตัวแปรแฝงวิดีโอและการกระทำ ในขั้นตอนการอนุมาน การทำนายของโมเดลจะถูกดำเนินการในโลกจริงแบบอะซิงโครนัส ในขณะที่ผลการสังเกตจริงจะถูกป้อนกลับเข้าไปในแคช KV เพื่อป้องกันไม่ให้ข้อผิดพลาดสะสมตามเวลา
ผลการทดลอง
ทีมวิจัยได้แสดงความสามารถของ DreamZero ภายใต้หกการตั้งค่า — ห้าอย่างสำหรับการทดสอบการสรุป และหนึ่งอย่างสำหรับการใช้งานแบบเรียลไทม์
ข้อมูลการฝึกที่เกี่ยวข้องและการสาธิตผลการทดลองสามารถดูได้ที่ลิงก์ต่อไปนี้:
https://dreamzero0.github.io/evals_gallery/
การฝึกฝนล่วงหน้า AgiBot: งานที่เคยเห็น & ไม่เคยเห็น
ทีมวิจัยทำการประเมินโมเดลที่ฝึกฝนล่วงหน้าแบบใช้ได้ทันที: งานมาจากการกระจายตัวของการฝึกฝนล่วงหน้า แต่ทดสอบแบบ zero-shot ในสภาพแวดล้อมใหม่ที่มีวัตถุที่ไม่เคยเห็น DreamZero (รวมถึงเวอร์ชันที่ฝึกจากศูนย์) บรรลุความคืบหน้าเฉลี่ยของงานที่ 62.2% เพิ่มขึ้นมากกว่า 2 เท่าเมื่อเทียบกับเส้นฐาน VLA ที่ฝึกฝนล่วงหน้าที่ดีที่สุด (27.4%) VLA ที่ฝึกจากศูนย์แทบจะเป็นศูนย์; VLA ที่ฝึกฝนล่วงหน้ามีความคืบหน้าบ้าง แต่มีขอบเขตจำกัด

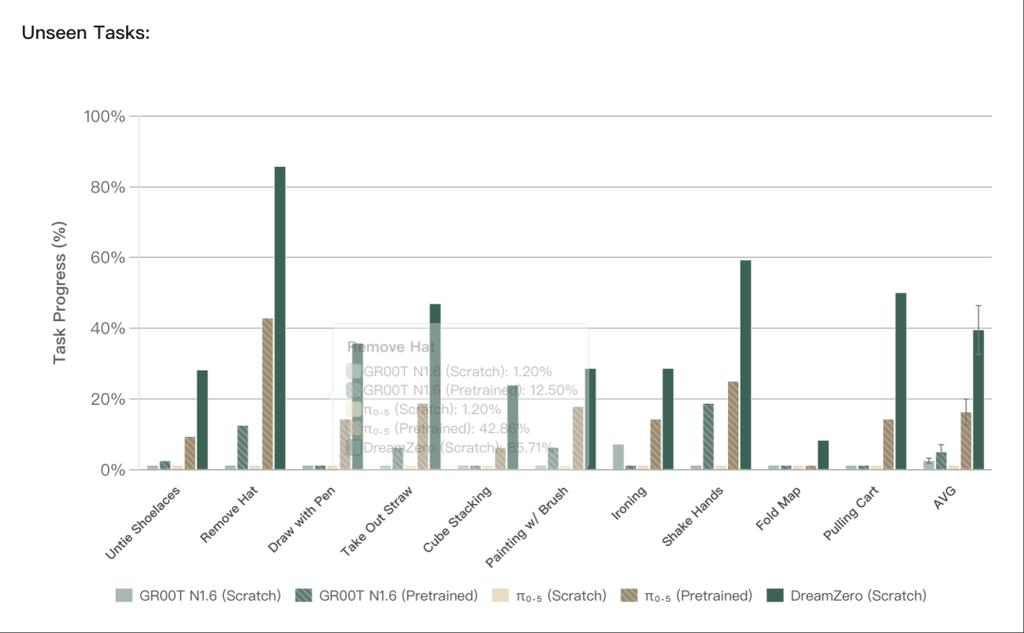
สำหรับงานที่ไม่ได้ปรากฏในการฝึกฝนเลย (เช่น การแก้เชือกรองเท้า การจับมือ) DreamZero ยังคงบรรลุความคืบหน้าของงานที่ 39.5% ในขณะที่ VLA ยังคงแสดงความยากลำบากอีกครั้ง เป็นที่น่าสังเกตว่าความคืบหน้าที่จำกัดของ VLA ที่ฝึกฝนล่วงหน้าในงานที่ไม่เคยเห็น ส่วนใหญ่เกิดจากแนวโน้มที่จะดำเนินการกระทำเริ่มต้น “จับ-วาง” โดยไม่คำนึงถึงคำสั่ง ซึ่งแสดงให้เห็นว่ามัน overfit กับพฤติกรรมการฝึกฝนที่โดดเด่น แทนที่จะเข้าใจความหมายของงานใหม่อย่างแท้จริง ทีมวิจัยทำการ rollouts 80 ครั้งสำหรับแต่ละจุดตรวจสอบ บนหุ่นยนต์ 4 ตัว ในสภาพแวดล้อมและวัตถุที่แตกต่างกัน
DROID: งานที่เคยเห็น & การกระทำที่ไม่เคยเห็น
เพื่อตรวจสอบผลลัพธ์บนข้อมูลสาธารณะ ทีมวิจัยฝึกฝน DreamZero บน DROID (หนึ่งในชุดข้อมูลหุ่นยนต์โอเพ่นซอร์สที่ต่างกันมากที่สุด) และประเมินงานที่เคยเห็น 20 งานและงานคำกริยาที่ไม่เคยเห็น 20 งาน (การกระทำที่ไม่ได้ปรากฏใน DROID) DreamZero ทำได้ดีกว่าเส้นฐานที่ฝึกฝนล่วงหน้าอย่างมีนัยสำคัญ บรรลุความคืบหน้าของงานที่ 49% ในคำกริยาที่ไม่เคยเห็น ในขณะที่ VLA ที่ทันสมัยที่สุดมีเพียง 25–32%

การฝึกฝนภายหลัง: การสรุปนอกการกระจายตัว
ส่วนนี้ศึกษาว่า WAM ยังคงรักษาความสามารถในการสรุปไว้หรือไม่หลังจากปรับแต่งเฉพาะงาน ทีมวิจัยทำการฝึกฝนภายหลังในสามงานย่อย: พับเสื้อ, บรรจุผลไม้, ทำความสะอาดโต๊ะ DreamZero แสดงผลที่แข็งแกร่งกว่าในทั้งสามงาน ซึ่งบ่งชี้ว่ายังคงรักษาความสามารถในการสรุปสภาพแวดล้อมไว้หลังการฝึกฝนภายหลัง
การถ่ายโอนข้ามรูปธรรม
ด้วยข้อมูลการเล่นเพียง 30 นาที (55 แทร็ก) DreamZero สามารถปรับให้เข้ากับหุ่นยนต์ YAM และบรรลุการสรุปแบบ zero-shot สำหรับวัตถุใหม่ เช่น ฟักทอง, หมีเท็ดดี้, ถุงกระดาษ ในขณะเดียวกันก็แสดงความสามารถในการปฏิบัติตามคำสั่งภาษาที่แข็งแกร่ง ความรู้จากการฝึกฝนล่วงหน้า AgiBot สามารถถ่ายโอนได้โดยตรง โดยไม่ต้องฝึกฝนใหม่ขนาดใหญ่ นี่คือการถ่ายโอนเชิงรูปธรรมที่มีประสิทธิภาพสูงสุดในปัจจุบัน: งานที่เคยต้องการการสาธิตหลายร้อยชั่วโมง สามารถทำได้ภายใน 30 นาที (ไม่ใช้ข้อมูล YAM อื่นใด)
การป้อนคำสั่งแบบโต้ตอบ
ยุคของการป้อนคำสั่งสำหรับโมเดลพื้นฐานของหุ่นยนต์ได้มาถึงแล้ว ทีมวิจัยแสดงการป้อนคำสั่งแบบโต้ตอบในทางปฏิบัติ: พาหุ่นยนต์ไปยังสถานที่ต่างๆ และให้ผู้คนเสนองานใหม่ด้วยภาษาโดยตรง หุ่นยนต์สามารถดำเนินการที่น่าประหลาดใจได้หลากหลาย
การอนุมานแบบเรียลไทม์
ผ่านการปรับปรุงในระดับโมเดล ระบบ และการนำไปใช้ DreamZero บรรลุการอนุมานแบบเรียลไทม์ที่ 150ms ต่อส่วนการกระทำ สนับสนุนการควบคุมวงปิดที่ 7Hz เมื่อรวมกับการอนุมานแบบอะซิงโครนัสและการทำให้ส่วนการกระทำราบรื่น กระบวนการดำเนินการจะลื่นไหลและตอบสนองได้เร็วยิ่งขึ้น ทีมวิจัยเปรียบเทียบผลลัพธ์ของจำนวนขั้นตอน diffusion 16/4/1: ยิ่งขั้นตอนน้อย ความล่าช้าก็ยิ่งต่ำ และ DreamZero-Flash ยังคงรักษาประสิทธิภาพไว้ได้แม้ในการอนุมานขั้นตอนเดียว ทีมวิจัยยังแสดงผลกระทบของการทำให้ส่วนการกระทำราบรื่นและการอนุมานแบบอะซิงโครนัสต่อคุณภาพการดำเนินการ
DreamZero (16 diffusion step) + async & action chunk smoothing
การสรุปแบบ zero-shot สามารถไปได้ไกลแค่ไหน? ทีมวิจัยยังคงทดสอบความทนทานของ DreamZero อย่างต่อเนื่อง โดยสำรวจขีดจำกัดความสามารถในงานที่ไม่เคยฝึกฝนมาก่อนและสภาพแวดล้อมที่ไม่เคยเห็น ตั้งแต่การพลิกเบอร์เกอร์ การกดปุ่มลิฟต์ ไปจนถึงการเคาะไซโลโฟน การเขย่าทัมเบอรีน โมเดลยังคงสร้างทักษะใหม่ที่น่าประหลาดใจออกมาอย่างต่อเนื่อง
DreamZero เป็นเพียงจุดเริ่มต้น — มันเป็นตัวแทนของคลื่นลูกใหม่ของโมเดลพื้นฐานหุ่นยนต์รุ่นใหม่ที่อิงตามโมเดลโลกวิดีโอ
ติดตาม “Whale Habitat” Mini Program เพื่อรับข่าวสาร AI ล่าสุด
⚠️ หมายเหตุ: เนื้อหาได้รับการแปลโดย AI และตรวจสอบโดยมนุษย์ หากมีข้อผิดพลาดโปรดแจ้ง
☕ สนับสนุนค่ากาแฟทีมงาน
หากคุณชอบบทความนี้ สามารถสนับสนุนเราได้ผ่าน PromptPay

本文来自网络搜集,不代表คลื่นสร้างอนาคต立场,如有侵权,联系删除。转载请注明出处:https://www.itsolotime.com/th/archives/22996