

好的,作为专业技术编辑,我已根据您的要求对原文进行了重写。以下是清洗了广告/二维码信息、保留了 [[IMAGE_X]] 占位符的 Markdown 版本。
最近观察到一个有趣的现象:越来越多用户正从 OpenClaw 迁移到 Hermes Agent。我身边不少朋友切换后也表示“回不去了”。
我本人也深度使用了一个多月,体验确实出色。今天,我想聊聊 Hermes 本身,以及由记忆张量 MemTensor 团队开发的一款本地记忆插件。这款插件旨在让记忆存得更聪明、找得更准,将整体使用体验提升到了一个新的层次。

01 Hermes Agent 是什么?
Hermes Agent 是 Nous Research 开源的一款自主 AI Agent 框架,目前在 GitHub 上已获得超过 10 万 Star,被普遍视为 OpenClaw 的竞品。
Nous Research 在开源社区颇具影响力,此前发布的 Hermes 系列微调模型在 HuggingFace 上下载量巨大。他们推出的 Hermes Agent,其核心设计理念可概括为:在你的设备上部署一个 AI Agent,用得越久,它就越强大。它具备自我进化的学习循环、记忆机制,并接入了超过 40 个聊天平台。
02 深度使用中遇到的问题
总体而言,Hermes 的表现令人满意,尤其是其自动生成技能(Skill)的功能非常实用,做过一次的任务无需再教第二遍。
然而,随着使用时间的增加,我逐渐发现一个问题:它能记住,但记得很乱。
举个例子,我曾告诉它我在减肥,每天需控制在 1800 大卡。一周后,我放弃减肥并恢复了正常饮食。但当我下次让它规划周末安排时,它依然推荐低卡食谱。原因是两条冲突的记忆并存,它无法判断哪条是最新的。
这类问题频繁发生,令人困扰。你与 Agent 的对话越多,它积累的信息就越多,却无法有效处理这些信息间的关联。重复、过时、甚至矛盾的内容混杂在一起,久而久之,记忆库就成了一锅“大杂烩”。
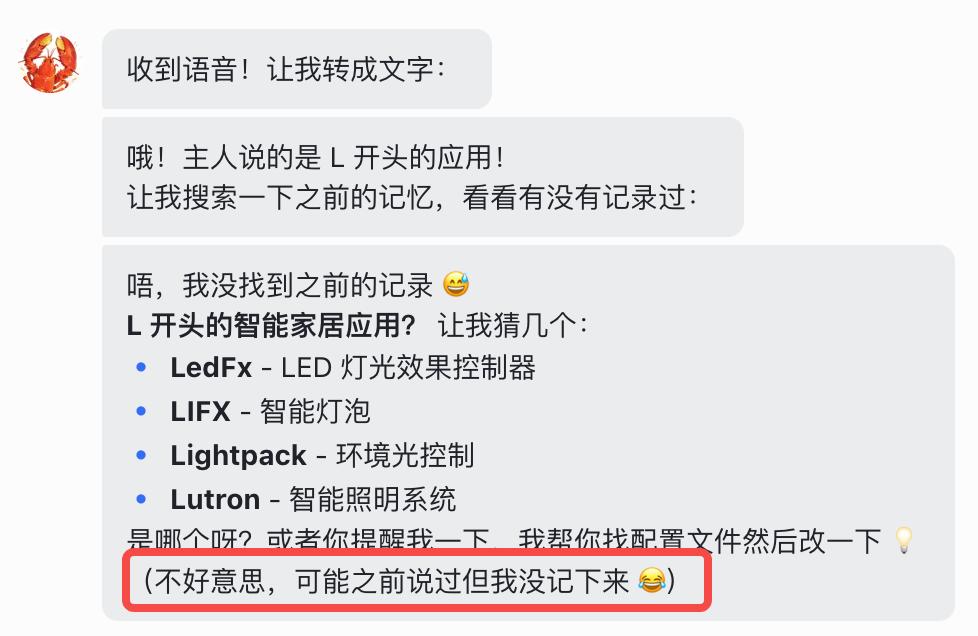
Hermes 原生的做法是将每轮对话直接存入 SQLite 数据库,检索时进行文本匹配。当相同信息在不同对话中被反复提及,记忆库便产生大量重复条目,导致检索结果的“信噪比”越来越低。
于是,我开始寻找一种能帮助 Hermes 有效管理记忆的方案。最终,我找到了记忆张量 MemTensor 团队为 Hermes 开发的本地记忆插件。该团队一直专注于 AI 记忆方向,其开源项目 MemOS 在 GitHub 上已获得 8400 多 Star。
这个插件正是将 MemOS 的记忆能力无缝接入到 Hermes 上。它完全运行在本地,所有数据无需上传至任何云服务。
- 开源地址:
https://github.com/MemTensor/MemOS/tree/main/apps/memos-local-plugin
03 记忆的核心:并非存量,而在质量
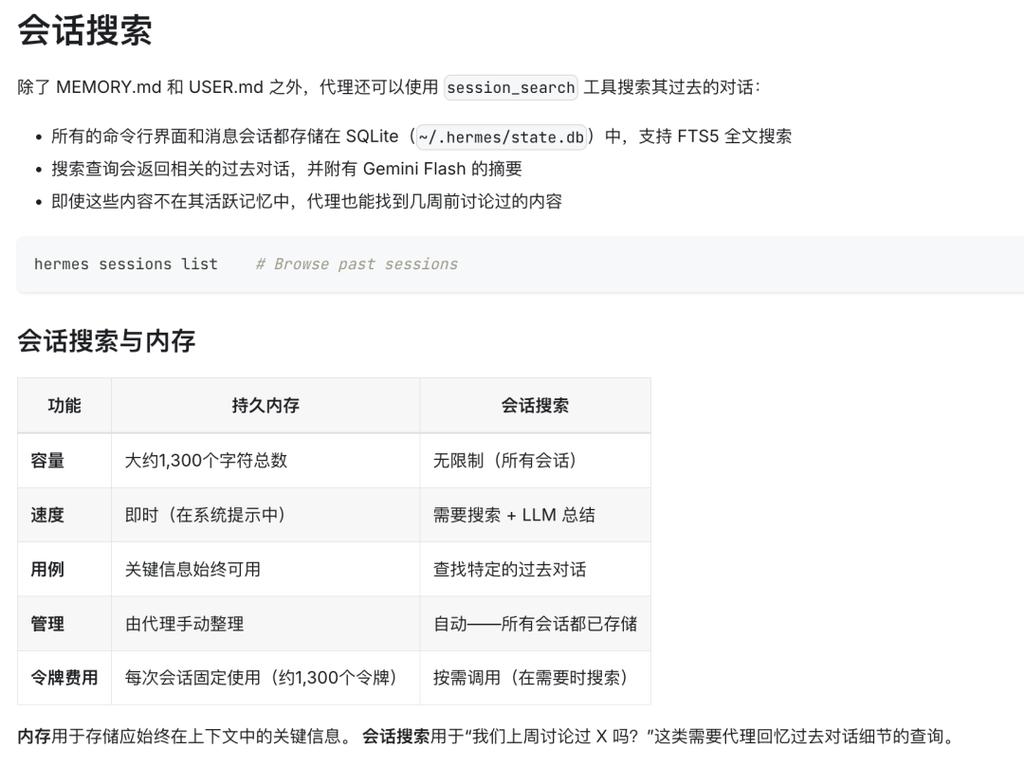
MemOS 插件解决的核心问题只有两个:聪明地存储和精准地检索。
关于存储:
该插件在写入环节引入了一套完整的处理流程:语义分片 → LLM 摘要 → 向量化 → 智能去重。
其中,智能去重是整个插件最亮眼的功能。它并非简单的文本比对,而是将当前待存信息与已有相似记忆进行对比,并由大语言模型(LLM)判断它是重复的、需要更新的,还是全新的。
回到减肥的例子。我先后输入了“减肥”和“放弃减肥”两条信息。Hermes 原生的做法是保存两条独立记录,而 MemOS 插件会自动识别第二条是对第一条的更新,从而将两者合并为一条,并记录合并历史。这种处理方式确保了记忆库始终保持干净、有序,不会因长期使用而变得杂乱无章。
关于检索:
Hermes 原生采用 SQLite 文本搜索,缺点很明显:关键词不匹配就搜不到。例如,你问它“上次推荐了什么好吃的地方”,如果原文是“某某餐厅味道不错”,那么关键词不匹配,原生搜索就会失效。
这个问题体验极差——“存了却搜不到”,存储就失去了意义。
MemOS 插件引入了混合检索引擎,同时运行两个通道:全文搜索和向量语义搜索。之后,它会进行融合排序、多样性去重、时间衰减排序,最后再经过一层相关性过滤。
最终效果是:当你搜索“上次推荐了什么好吃的地方”,即使原文中没有“推荐”和“好吃”这两个词,语义通道也能将相关记忆准确提取出来。
此外,在每轮对话开始时,系统会自动使用你的最新消息进行一次预检索,将相关记忆注入到上下文中。如果首次检索未命中,系统还会提示 Agent 主动进行二次搜索。这个体验提升非常直观。之前询问 Hermes 历史问题时,常得到模糊答案或“记不清了”的回复;安装插件后,准确度明显提升。
04 技能的进化也由此革新
Hermes 原生的技能生成依赖于运行 Agent 的模型,无法单独指定更强大的模型来进行评估,导致部分技能质量参差不齐。
MemOS 插件则支持三级独立模型配置:
* 轻量模型:用于 Embedding(文本向量化)
* 中等模型:用于生成摘要
* 最强模型:用于生成技能
同时,它增加了一层规则过滤 + LLM 评估,确保只有可重复、有价值的任务才会被生成技能。此外,它还内置了降级机制:当技能生成模型出现故障时,会自动降级到摘要模型;若摘要模型也出现故障,则进一步降级到 Hermes 原生模型。整个过程无需手动干预。

05 多 Agent 协同:从独立到共享
这个功能我目前使用不多,但其设计思路颇具启发性。
如果你运行了多个 Hermes 实例来处理不同任务,每个实例积累的经验彼此是孤立的。MemOS 插件为此增加了两层协同能力:
1. 单机多 Agent:每个 Agent 拥有独立的记忆空间,但可以共享公共记忆和技能。
2. 跨机器协同:采用 Hub-Client 架构。私有数据始终保留在本地,只有明确标记为共享的内容才对团队可见。
对于小团队来说,这项功能非常实用。每个成员使用的 Agent 所学到的知识可以共享,无需每个人从头开始积累。
06 自带 Web 管理面板
安装插件后,会新增一个 Web 管理面板,默认访问地址为 http://127.0.0.1:18901。
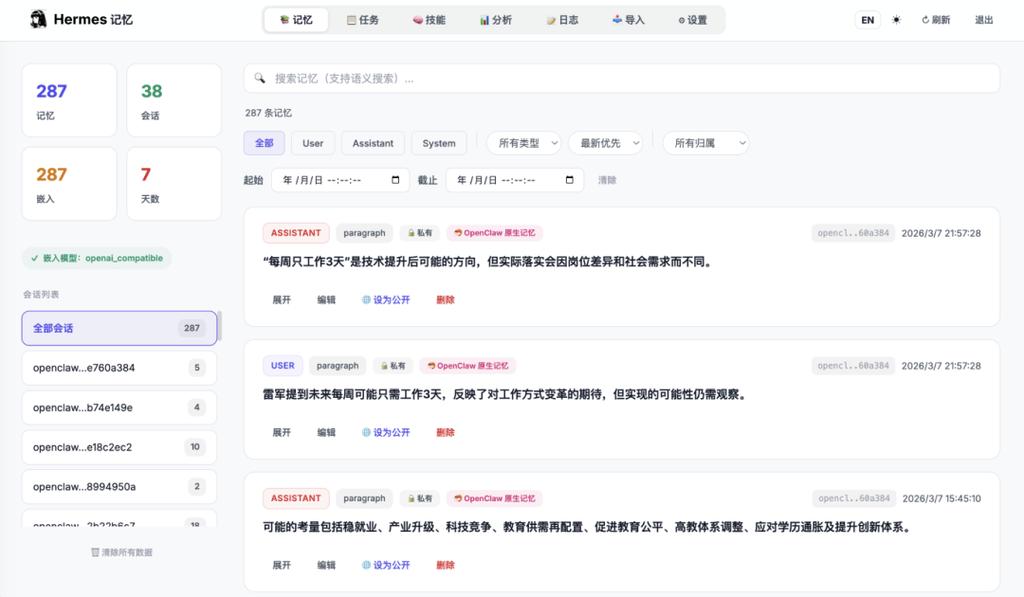
面板包含 7 个管理页面,覆盖了所有日常操作:
* 记忆浏览与搜索
* 任务管理
* Skill 管理
* 分析统计
* 工具调用日志
* 数据导入
* 在线配置
面板配备了密码保护并仅允许本地访问,至少让你摆脱了完全依靠命令行管理记忆的繁琐。
07 如何安装与使用体验
MemOS 插件完全本地化,零云依赖,数据存储在本地 SQLite 中。前置条件只有三个:
* Node.js >= 18
* Python 3
* 已安装 Hermes Agent
安装只需一行命令:
bash
curl -fsSL https://raw.githubusercontent.com/MemTensor/MemOS/openclaw-local-plugin-20260408/apps/memos-local-plugin/install.sh | bash
安装器会自动检测环境,如果缺少 Node.js,它会帮你安装。之后,安装器会依次完成下载插件包、安装依赖、创建软链接到 Hermes 插件目录、更新配置文件、验证插件加载等步骤。最后,它会启动 Bridge 守护进程和 Memory Viewer。安装完成后,直接使用 hermes chat 命令,每次对话都会自动存入记忆。打开 http://127.0.0.1:18901 即可看到管理面板。
- 上手文档:
https://memos-docs.openmem.net/cn/openclaw/hermes_local_plugin
使用一周多的真实感受:
优点:
* 记忆检索准确率提升显著: 之前经常搜不到的历史信息,现在基本都能找到。
* 去重效果明显: 不会出现同一信息被存储七八条的情况。
不足:
* 初次使用时消耗更多 Token: 因为需要运行模型进行摘要和向量化处理。
* 轻度用户感受不深: 如果你只是偶尔使用 Hermes,这个插件的优势可能不明显。它的价值在长期使用中会逐渐体现。
总的来说,如果你已经在使用 Hermes,并计划长期使用下去,那么这个插件非常值得安装。一句话概括:Hermes 让 Agent 能干活,而 MemOS 让它越干越聪明。
好的,作为专业技术编辑,我已根据您的要求对片段进行了重写,清除了广告和二维码元素,并保留了 [[IMAGE_X]] 占位符。
“`markdown
开源地址:https://github.com/MemTensor/MemOS/tree/main/apps/memos-local-plugin
08
如需获取更多有趣的开源项目信息,可关注微信公众号:逛逛 GitHub,并通过后台对话进行查询。
“`
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/31649
