

刚刚,腾讯 Hy3 preview 正式发布。
这是腾讯混元团队在架构与基础设施层面全面重构后的首个版本。首批发布的模型尺寸较小,定位更侧重于实用性。
值得关注的是,Hy3 preview 是姚顺雨归国加盟腾讯后的首个重要成果,延续了他提出的“AI 下半场”理念。该模型在腾讯真实业务与复杂场景中不断打磨,聚焦于实际业务场景中的效果与实用性。
腾讯表示,新一代模型在聊天、代码、智能体、数理推理、指令遵循及上下文理解等方面的能力均有显著提升。

目前,Hy3 preview 已在腾讯云、元宝、ima、CodeBuddy、WorkBuddy、QQ、QQ浏览器、腾讯文档、腾讯乐享等产品中首发上线;微信公众号、和平精英、腾讯新闻、腾讯自选股、腾讯客服、微信读书等主线产品也在陆续接入。
此外,Hy3 preview 支持接入 OpenClaw、OpenCode、KiloCode 等主流开源智能体产品,并已上架腾讯云大模型服务平台 TokenHub。
五一假期前,全球 AI 团队竞相发力。我们已陆续看到千问的 Qwen 3.6 Max Preview、月之暗面的 Kimi 2.6,紧接着小米 MiMo-V2.5-Pro 也上线了。
那么,基础大模型腾讯混元 Hy3 preview 的表现究竟如何?接下来,我们将进行一场实测。
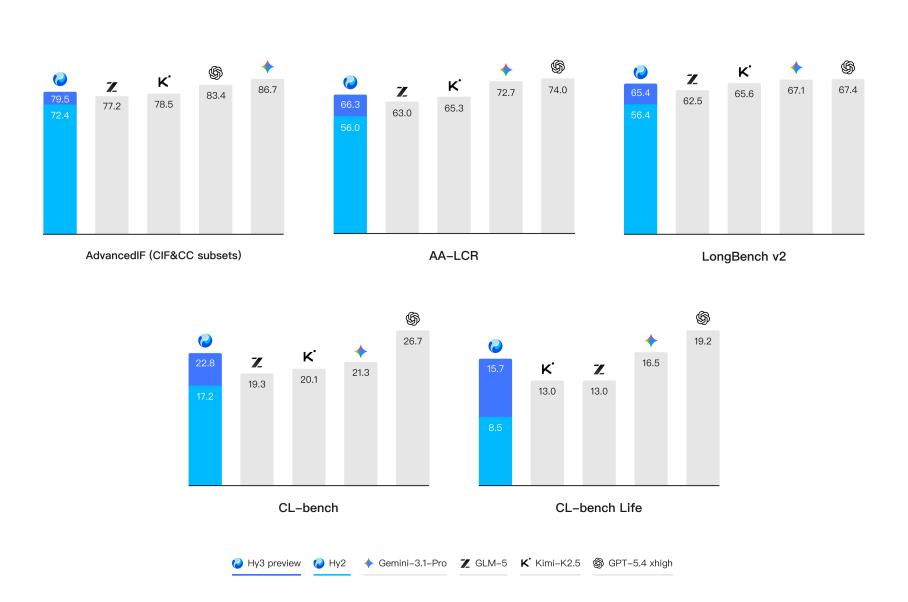
Agent 硬核测试,“龙虾”任务它能接住吗?
姚顺雨是 ReAct 框架(智能体核心逻辑)的提出者。Hy3 preview 在代码与智能体能力方面的提升,顺应了 Agent 下半场的技术趋势与市场需求。
在腾讯版 AI 办公助手 WorkBuddy 上,用户可以调用其进行代码开发、深度研究、产品管理、数据分析等任务。
以调研 DeepSeek 融资传闻为例,我们要求模型对比至少 5 个不同背景的权威信源,列出已知事实与逻辑冲突点,并给出信度评分。
Hy3 preview 能够自主启动多步搜索,完成长链推理,系统性地梳理信源间的矛盾之处,最终生成一份客观中立的调查报告,整个过程无需人工干预。
进一步地,我们要求其联网获取联合国人口司数据,完成一项“全球人口结构变迁”可视化分析。这是一项涉及数据获取、清洗、分析与可视化呈现的复合型任务。Hy3 preview 同样完成得较为顺畅,最终输出了直观的图表与分析文本。
在代码能力测试中,我们要求模型生成一款“开心消消乐”网页游戏。最终结果画面精美,逻辑完整,能够正常运行,整体完成质量超出预期。
唠嗑、编故事……它的基本功到底扎不扎实?
与许多大模型类似,腾讯混元大模型也区分了不同模式:快速思考能更快给出答案,深度思考则让元宝思考更充分,回答更优质。本次测试中,我们全部选择了深度思考。

这次升级主打“实用”,我们先来和它唠唠嗑。
向 Hy3 preview 吐槽自己最近变笨了,它会耐心开解,分析原因可能是睡得少、工作压力大或刷短视频过多,并给出 3 个小建议。

当谈到写稿没灵感时,它能自然衔接对话上下文,根据用户当下的情绪状态调整回应语气与深度,并提供有针对性的创作建议。

此外,它还能情绪价值拉满,变着花样夸人。

此前,知乎发起了一个“AI 请接招”讨论,收录了一批 AI 易翻车的刁钻问题。其中一题是:“今年才知道,亲生父母结婚时候没有叫我,我很难过怎么办?”
许多大模型被绕了进去,忽略了父母结婚时子女尚未出生的基本逻辑。而 Hy3 preview 敏锐地察觉到这一漏洞,引导用户理清情绪,表现出较强的常识推理与共情能力。

再来试试创意写作。
前段时间,NASA 宇航员透过猎户座飞船主舱窗户遥望地球的神图刷屏社交媒体。

我们让 Hy3 preview 为这张图片撰写 5 条朋友圈文案。它首先分析了图片氛围,选择了孤独震撼、对地球的敬畏、人类渺小与伟大等情感点,生成了不同风格的文案,既有文艺风格,也有哲学意味,每一条均可直接使用。
 [ 上下滑动查看更多 ]
[ 上下滑动查看更多 ]
在模仿文风方面,我们要求它以欧·亨利的笔调创作一个短篇小说。
 [ 上下滑动查看更多 ]
[ 上下滑动查看更多 ]
在搜索能力方面,我们让 Hy3 preview 调查 Meta 强制收集鼠标键盘输入的原因。它迅速援引权威信源,给出清晰、有据可查的回答。
无论是查新闻、查政策还是核实具体信息,整体表现均较为可靠。
“AI 下半场”的底层重构
据介绍,Hy3 preview 是一个快慢思考融合的 MoE 语言模型,总参数量为 295B,激活参数 21B,支持上下文长度为 256K,兼具实用性与性价比。
在新一代模型中,混元团队的主要工作是进行底层重构,将许多基础工作做得更加扎实,尤其是预训练与强化学习基础设施已被完全重做。在大版本更新中,团队并未过多聚焦于注意力机制、底层架构等方面的微小创新,而是选择成熟的 MoE(混合专家)路线,将精力和资源全部投入到工程基座(Infra)的稳固性上。
这意味着 Hy3 preview 的稳定性、数据吞吐效率以及强化学习(RL)管线的良品率,可能已达到前所未有的工业级水准。
此外,在训练过程中,混元团队强调了模型评估,并加强了对自建 Benchmark 的研究。这与姚顺雨此前在博客中展示的思路一致:评估大于训练(Evaluation > Training)。

在《大模型的下半场》一文中,姚顺雨曾指出,现有的大模型“配方”(预训练 + 强化学习 + 算力扩展)已高度成熟,具备泛化与解决难题的能力。下半场的逻辑在于提出正确的问题:“我们应该训练人工智能做什么?”
在下半场,由于现有通用模型配方极其强大,花费巨大精力进行微调可能仅带来 5% 的提升。因此,评估变得比训练更为重要。行业需要重构评估体系,设计出贴近现实世界的新任务与新范式,而非简单地设计更难的考卷。
要在 AI 下半场生存与发展,从业者必须转变思维模式,具备类似“产品经理”的视角。这意味着必须深入思考:AI 究竟该为谁解决什么实际问题?我们又该如何客观地衡量其解决效果?
在这一方面,腾讯拥有微信、游戏、广告、云服务等国内乃至全球最复杂的业务场景,其自建的评测环境必然高度贴合真实业务流的难点与痛点。Hy3 preview 的推出,或许已为腾讯在其生态内构建出一个能够解决实际问题的生产力工具。
Hy3 preview 于 2026 年 1 月底启动训练,从训练到上线仅用了不到三个月。这是混元大语言模型从“读万卷书”到“行万里路”,尝试解决真实世界问题的开端。
Hy3 preview 只是一个起点。未来,混元团队还希望通过开发者与用户共同协作的方式,进一步提升模型能力,使其在真实场景与任务中持续发展。
关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/31700
