


随着人工智能技术的飞速发展,DeepSeek 作为一款强大的语言模型,受到了广泛关注。为了更好地满足个性化需求和保障数据安全,本地化部署 DeepSeek 成为了许多用户的选择。
一、部署前的准备
- 硬件环境:DeepSeek 模型对硬件有一定要求,建议使用配备 NVIDIA 显卡的电脑,显存最好≥8GB,同时预留 20GB 左右的磁盘空间。
- 软件环境:需要安装 Ollama,它是一个轻量级的本地 AI 模型运行框架,支持跨平台安装,包括 macOS、Windows 和 Linux。
二、DeepSeek 本地化部署的详细步骤
- Ollama 的安装与配置
- 下载安装:访问 Ollama 官网https://ollama.com/,根据操作系统选择对应的安装包进行下载。例如,在 Windows 系统中,可直接下载安装包并双击安装,安装过程中保持默认选项即可。

- 验证安装:安装完成后,通过终端输入
ollama --version命令来验证安装是否成功,若能显示版本号则表示安装成功。
- DeepSeek 模型的下载与加载
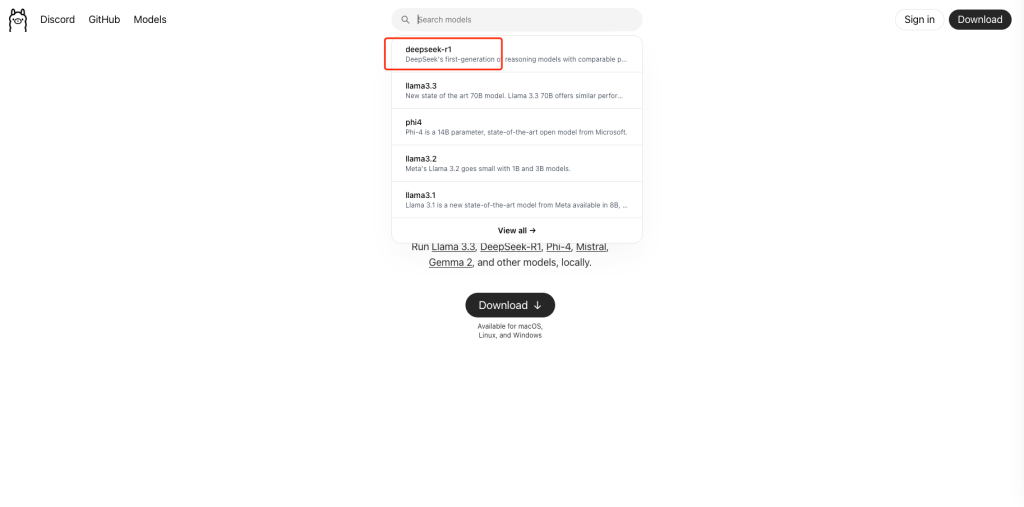
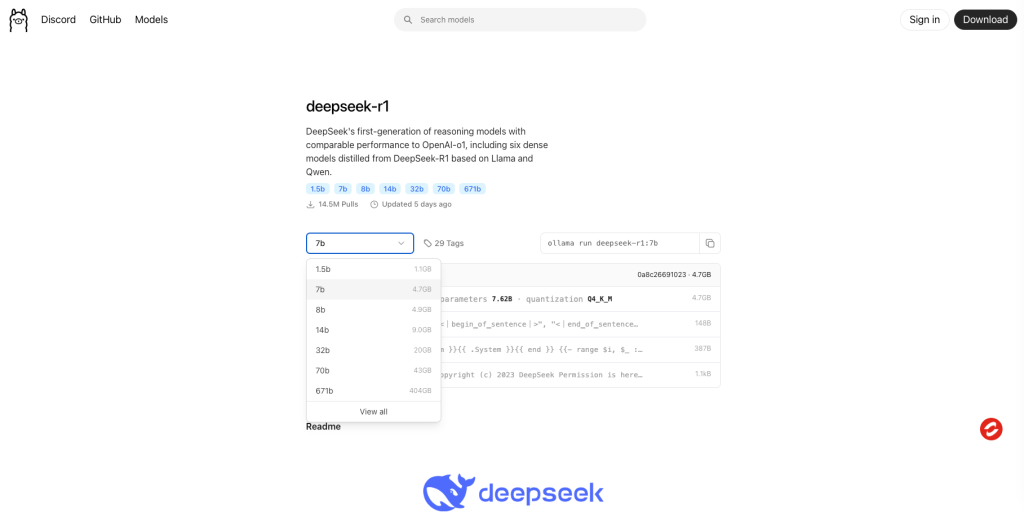
- 选择模型版本:Ollama 支持多种 DeepSeek 模型版本,用户可根据硬件配置进行选择。如入门级的 1.5B 版本适合初步测试,中端的 7B 或 8B 版本适合大多数消费级 GPU,而 14B、32B 或 70B 等高性能版本则适合高端 GPU。
- 下载模型:在终端输入相应命令下载模型,例如,下载 7B 版本的命令为
ollama run deepseek-r1:7b。
- 模型加载与验证:下载完成后,可通过运行交互式对话测试来验证模型是否成功加载。如输入“请用 Python 写一个快速排序算法”,若能看到完整代码输出,则说明模型已成功加载。
- 交互界面的搭建
- Chatbox:Chatbox 是一个开源的用户界面工具,用户可在其官网https://chatboxai.app/en或 GitHub 上下载安装所需的版本https://github.com/Bin-Huang/chatbox。安装完成后,选择“使用自己的 API Key 或本地模型”,在设置页面中选择 OLLAMA API,模型选择 deepseek-r1:70b 等相应版本,即可开启问答模式。
- Open WebUI:若想通过浏览器与 DeepSeek 模型进行交互,可使用 Open WebUI。首先确保机器上已安装 Docker,然后运行相应命令安装并启动 Open WebUI,安装完成后访问
http://localhost:3000,选择 deepseek-r1:latest 模型即可开始使用。
三、本地化部署的优势与注意事项
- 优势:本地化部署 DeepSeek 可以实现数据的本地存储和处理,有效保障数据安全和隐私。同时,用户可以根据自身需求对模型进行个性化定制,无需受网络限制,随时随地使用 DeepSeek 进行各种任务。
- 注意事项:在部署过程中,要确保硬件设备满足模型运行的要求,否则可能会影响模型的性能。此外,由于 DeepSeek 模型文件较大,下载过程可能需要一定时间,用户需耐心等待。在使用过程中,若遇到问题可参考相关教程或社区资源进行解决。
通过以上步骤,用户就可以成功地在本地部署 DeepSeek 模型,打造属于自己的智能助手,充分发挥其在自然语言处理等领域的强大功能。
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/4250
