


硅谷正为DeepSeek的新模型沸腾!仅3B参数却带来指数级效能突破,被业内评价为“将谷歌Gemini严防死守的核心技术开源了”。唯一的小争议,或许是它那个略显直白的命名——“DeepSeek-OCR”。


这一模型直面大模型处理长文本时算力激增的痛点,以“视觉压缩文本”的思路实现四两拨千斤。其背后理念极为简洁:既然一张图能承载海量文字(且占用更少token),何不将文本信息转化为视觉表征进行压缩?正如人类阅读时扫视即可理解,无需逐字解码。
实验证明,当文本token数在视觉token数的10倍以内时,模型解码准确率高达97%;即便压缩率提升至20倍,准确率仍保持在60%左右。
更令人瞩目的是其极致的效能表现:仅需一张A100-40G GPU,每日即可生成超20万页高质量训练数据。研究成果甫一发布,GitHub迅速收获3.3K星,HuggingFace热榜跃居第二,X平台热议如潮。
AI专家卡帕西直言欣赏这一设计,特别指出“图像比文字更适合作为LLM输入”的巧思;更有评论称此为“AI的JPEG时刻”,为记忆架构开辟全新路径;甚至有人推测,这相当于公开了谷歌Gemini的核心机密。

同时,这项研究也引发深层思考:这种统一视觉与语言的方法,是否将成为通向AGI的关键路径?论文中还探讨了模拟人类记忆的“遗忘”机制,为长上下文处理提供了新视角。
▍技术核心:双组件协同实现高效压缩
DeepSeek-OCR的核心架构包含两大组件:
- DeepEncoder编码器:将图像转化为高密度视觉token
- DeepSeek3B-MoE-A570M解码器:从压缩token中重构文本
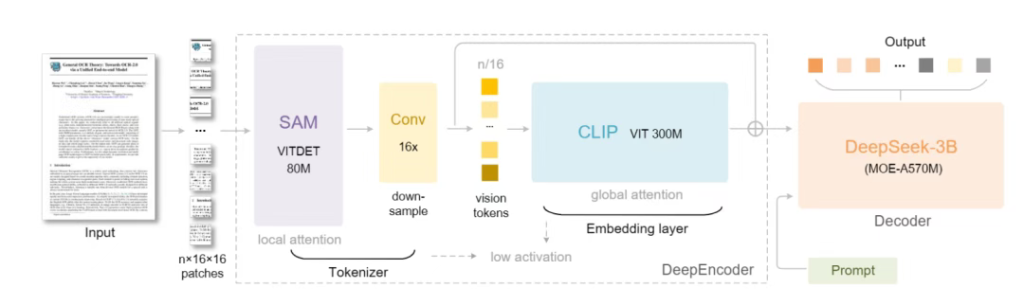
其中,DeepEncoder采用三阶段串行设计:
- 局部处理:基于SAM-base模型进行细粒度特征提取
- 特征压缩:通过16倍卷积层大幅削减token数量
- 全局理解:利用CLIP-large模型深度解析浓缩特征
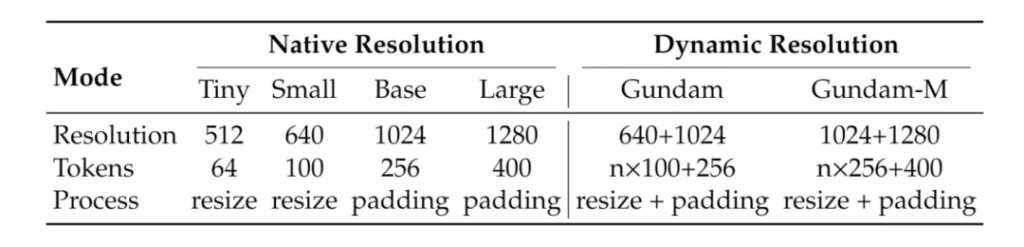
该编码器支持从“Tiny”(64token)到“Gundam”(近800token)的多级压缩模式,可根据任务需求动态调整压缩强度。
在OmniDocBench基准测试中,DeepSeek-OCR以最少视觉token达到最优性能:仅100token即超越GOT-OCR2.0的256token表现;400token便可媲美原SOTA模型;不到800token即显著超越MinerU2.0的近7000token效果。
▍研究团队与创新展望
本研究由三位研究人员主导:
- Haoran Wei:曾主导GOT-OCR2.0开发,持续深耕端到端文档解析
- Yaofeng Sun:参与DeepSeek多代模型研发
- Yukun Li:谷歌学术引用近万次,深度参与V2/V3等模型开发
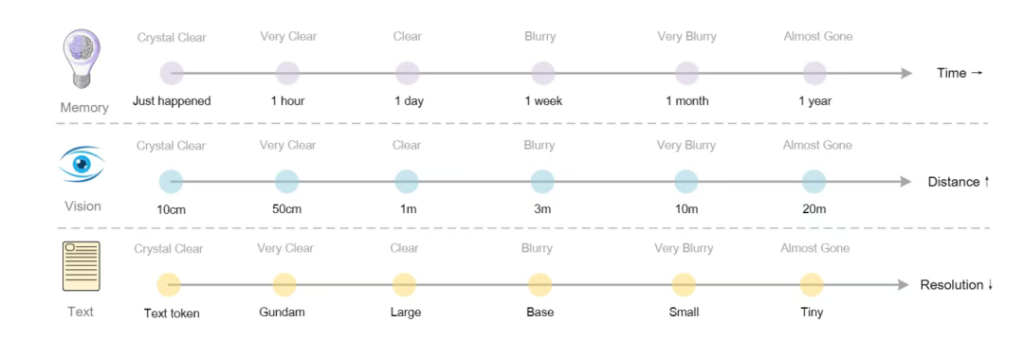
团队还提出一项前瞻构想:通过光学压缩模拟人类记忆机制。将近期记忆渲染为高分辨率图像保留细节,远期记忆则渐进压缩实现自然“遗忘”,这或许为构建无限长上下文架构提供了新方向。
这种更接近人类智能的处理方式,有望解决传统方法中计算资源随上下文长度暴涨的难题。
资源入口:
Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-OCR
GitHub:https://github.com/deepseek-ai/DeepSeek-OCR
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/4351
