


最近科技圈可一点都没闲着,各家都在密谋放大招。先是传了很久的 Claude 4.5 预计未来一两周内亮相,Google 的 Gemini 3 也瞄准了咱们国庆档期。不过今天我们要重点聊的,是 DeepSeek 家的两条新动态——V4 和 V3.2。
关于 DeepSeek-V3.2 的最新线索
有开发者发现,DeepSeek 团队在 HuggingFace 上悄悄创建了名为 “DeepSeek-V3.2-Base” 的模型卡。有意思的是,这个页面在一个下午内反复出现又消失了好几次,这种“欲盖弥彰”的操作反而坐实了新版本的存在。
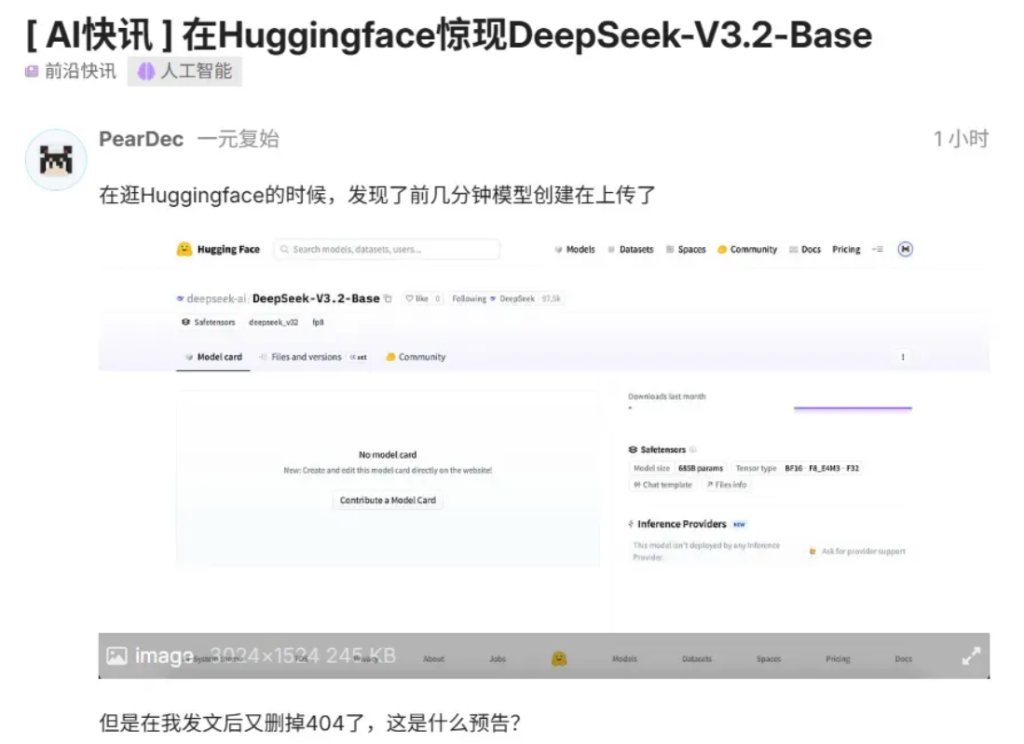

比起网上流传的各种猜测,这条来自官方渠道的线索显然更值得关注。不少人猜测,这可能是为接下来的 V4 版本做预热——是不是颇有 OpenAI 的营销风格?
DeepSeek-V4:性能大幅跃升
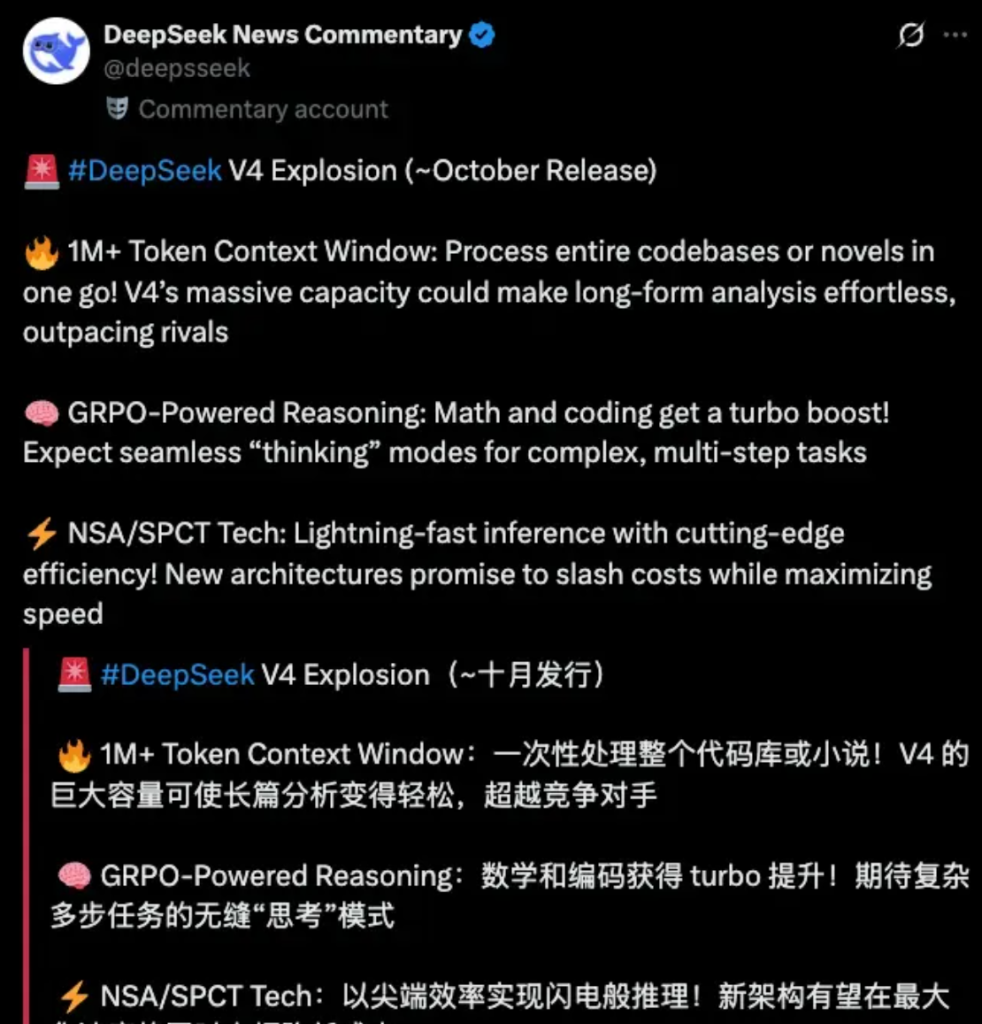
根据社区爆料,DeepSeek V4 计划在10月发布,而且这次不只是版本号升级那么简单。据传它将带来三大突破:
- 上下文窗口扩展至 1M Tokens
- 支持 GRPO Turbo 多步思考模式
- 推理速度更快,成本更低
后两点尤其可信。回顾2023年以来,Qwen 和 DeepSeek 的技术路线就有着诸多相似之处。比如 GRPO 算法年初随 DeepSeekMath 发布后,年中的 Qwen2-Math 就展示了相似的技术特征。虽然当时 GRPO 尚未开源,但技术思路的同步确实引人遐想。
技术前瞻:长文本处理将迎新突破
值得一提的是,Qwen 最近发布的 Qwen3-Next 采用了原生稀疏注意力(NSA)技术。该技术通过选择性计算关键词关系,有效解决了长序列处理中的计算瓶颈。这也让 DeepSeek V4 实现 1M 上下文窗口的传闻显得更加合理——毕竟两家在长文本技术上的进展一直相辅相成。
最后确认个好消息:这些新模型都会开源!
以上就是本期全部爆料。哪个模型最让你期待?欢迎在评论区分享你的看法~
参考资料:
[1] https://x.com/deepsseek/status/1972426156222611688
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/4118
