




在人工智能多模态领域,一个长期存在的核心挑战是如何构建既能深度理解语义又能精确重建像素的统一表征模型。传统方法往往在这两个目标间面临艰难权衡:专注于语义理解的模型(如基于CLIP的编码器)在图像重建任务中表现欠佳,而专注于像素重建的模型(如VAE)则语义理解能力有限。本文深入分析北京大学与阿里通义万相实验室联合提出的UniLIP模型,探讨其如何通过创新的两阶段训练框架和双条件架构,成功突破这一根本矛盾。
多模态统一模型的核心需求在于视觉表征必须同时兼顾高级语义理解和底层像素细节。早期基于变分自编码器(VAE)的方法因语义表征能力不足,在复杂理解任务上表现受限。近年来,基于对比语言-图像预训练(CLIP)的统一编码器成为主流,但它们面临理解与重建的内在冲突:直接量化CLIP特征会损害其卓越的语义理解性能;而为冻结的CLIP训练解码器,又因特征缺乏像素级细节而无法实现精确重建。例如,代表性工作RAE使用冻结的DINOv2进行重建,峰值信噪比(PSNR)仅达到19.23,远未达到实用标准。

UniLIP的创新之处在于提出了一套完整的CLIP微调框架,通过两阶段重建训练与自蒸馏损失的巧妙结合,在不损失模型原有理解性能的前提下,实现了卓越的图像重建能力。这一突破性设计使得UniLIP能够直接替换现有大型多模态语言模型(如InternVL)中的CLIP模块(如InternViT),并保持甚至略微提升其理解性能。与仅在ImageNet上进行有限实验的RAE相比,UniLIP进行了大规模的生成和编辑训练,仅用1B和3B参数规模,便在GenEval(0.90)、WISE(0.63)和ImgEdit(3.94)等多个基准上取得了最先进的性能,媲美甚至超越了更大规模的模型。

方法细节方面,UniLIP的核心贡献在于“CLIP无损适应图像重建”方案。为解决CLIP特征因细节缺失导致的重建模糊问题,该方案基于包含CLIP、像素解码器及投影层的自编码器架构,实施了两阶段训练策略。

第一阶段为解码器对齐。此阶段冻结CLIP编码器,仅训练像素解码器和投影层,使其学习从固定的CLIP特征中重建图像。训练目标聚焦于最小化重建图像与原始图像之间的差异,为后续优化奠定基础。

第二阶段为自蒸馏微调。由于原始CLIP特征缺乏像素细节,第一阶段的重建质量存在上限。因此,此阶段共同训练CLIP编码器,并通过自蒸馏方法约束其特征分布,防止其偏离原始语义空间,从而在注入细节的同时保留语义理解能力。训练目标包含重建损失和特征蒸馏损失,其中特征蒸馏确保微调后的CLIP特征(

)与原始CLIP特征(
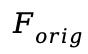
)保持语义一致性。

通过这一创新方案,UniLIP成功克服了语义理解与像素重建的内在权衡。实验表明,其理解能力甚至在部分基准上得到增强。对于生成与编辑任务,UniLIP特征带来了三大核心优势:首先,实现32倍高保真图像压缩,并能通过轻量级解码器高质量恢复;其次,继承CLIP的强文本对齐能力,确保对文本指令的精准响应;第三,提供完备的特征表示,同时编码高级语义与像素细节,为高保真编辑提供完整信息支撑。

在架构设计上,UniLIP提出了“用于图像生成和编辑的双条件架构”。

传统方法如MetaQuery范式,仅用固定数量的查询嵌入连接多模态语言模型与扩散模型,这在传递参考图像丰富的像素级细节时存在信息瓶颈,常导致编辑结果细节退化或内容不一致。UniLIP的创新双条件架构在查询嵌入之外,额外引入多模态语言模型的多模态隐藏状态作为第二个条件,共同引导扩散变换器(DiT)的交叉注意力模块。这种设计有效补充了缺失的像素级信息,成功将复杂任务解耦:多模态语言模型专注于高级推理和意图理解,扩散变换器则基于这套无损传递的、兼具高级语义与底层细节的丰富线索,进行高保真度的图像合成。
实验结果充分验证了UniLIP的有效性。模型架构方面,UniLIP包括1B和3B两个变体,分别由InternVL3与SANA集成而来,直接采用InternViT作为CLIP编码器,并结合DC-AE的像素解码器。训练数据涵盖BLIP3-o的38M预训练数据和60k指令微调数据,以及GPT-Image-Edit-1.5M的编辑预训练数据和ShareGPT-4o-Image的46K编辑数据。

在图像重建任务中,UniLIP在256×256分辨率下不仅超越了此前的量化方法,其更高的下采样率也带来了生成效率优势。在448×448分辨率下,与使用扩散解码器的Emu2相比,UniLIP由于打开CLIP进行重建训练取得显著优势。
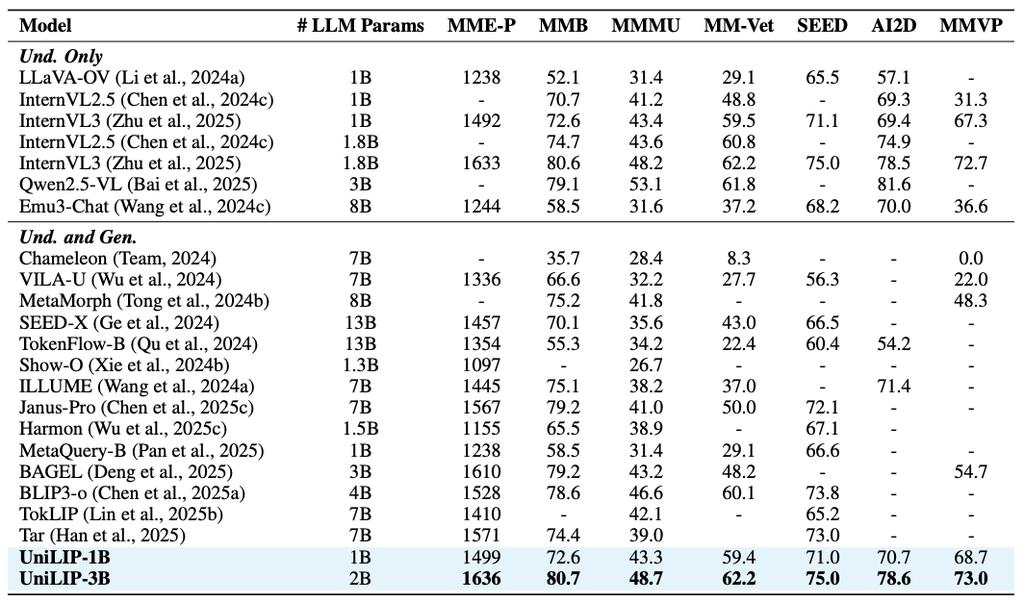
在多模态理解方面,UniLIP可以直接替换InternVL的视觉编码器进行测试。得益于重建训练对原始能力的有效保持,UniLIP实现了同规模最好的理解性能,并且超越了采用量化CLIP特征的更大模型如Tar(7B)和VILA-U(7B)。

在图像生成任务中,UniLIP在GenEval(0.90)和WISE(0.63)基准上,凭借卓越的文图对齐能力,不仅超越了同规模模型,还达到了与BAGEL等更大模型相当的水平。
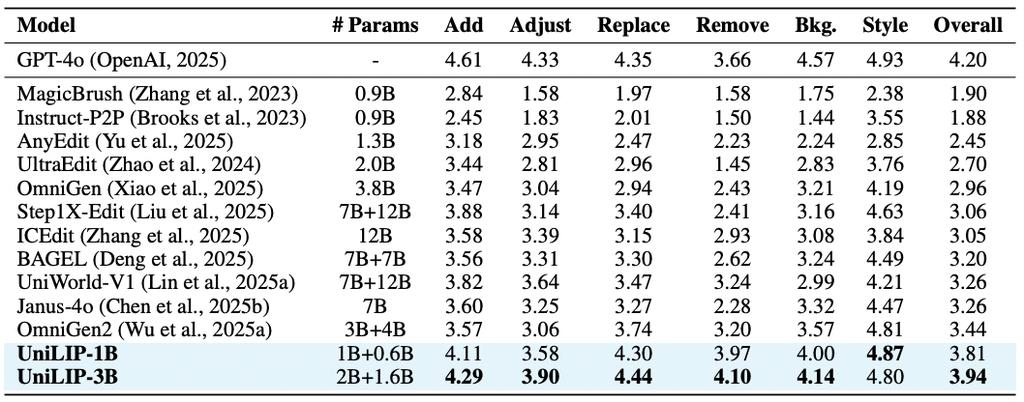
在图像编辑任务中,UniLIP在ImgEdit-Bench上以3.94的高分超越了OmniGen2等先进模型。其强大性能归功于UniLIP特征的丰富细节与精准语义对齐能力,以及双条件架构对这些特征的充分利用,确保了编辑的精确性和非编辑区的一致性。

可视化结果进一步证实了UniLIP的实用性。在生成任务中,UniLIP可以生成美观且严格遵循用户提示的图像;而在编辑任务中,UniLIP能够在准确修改图像的同时保持周围区域的一致性,展现了其在真实场景中的应用潜力。
综上所述,UniLIP通过精心设计的两阶段训练与自蒸馏约束,有效解决了语义理解与像素细节保留的矛盾,其创新的双条件架构为多模态模型的统一表征提供了新范式。这一突破不仅推动了多模态人工智能技术的发展,也为图像生成、编辑等实际应用开辟了新的可能性。
— 图片补充 —

关注“鲸栖”小程序,掌握最新AI资讯
本文来自网络搜集,不代表鲸林向海立场,如有侵权,联系删除。转载请注明出处:http://www.itsolotime.com/archives/8357
